There’s a phrase every software engineer with some experience immediately recognizes as a red flag. It’s not “I need this by tomorrow,” nor “can you take a quick look at this?” It’s far more subtle and dangerous:
“Hey, I’ve got some servers free this week, do you need them for anything?”
My boss said it with the nonchalance of someone offering you a cookie. What he was actually offering me were four H200 GPUs, 141 GB of VRAM each, 564 GB total. Hardware that on the spot market would easily cost you €50/hour if you’re lucky with the provider.
Available for a week. My vacation.
The problem I didn’t have before they lent me the hardware
The experiment was born at that moment, like all worthwhile projects: out of opportunity and a question that had been nagging me for a while.
The question was this: can an LLM truly understand chess, or does it just verbalize what the engine tells it?
The difference matters and isn’t obvious. A typical automated game annotation system works like this: Stockfish analyzes the position, finds that the move was a mistake, calculates the best alternative, and the LLM turns that into a sentence with words like “in this critical position, White should have preferred Nf6, maintaining pressure on the pinned e5 pawn.” It sounds exactly like a master would say it. But does the model understand that, or is it reformatting Stockfish’s output into natural language?
It’s the difference between a sports journalist who understands football and one who reads the match report aloud.
I have about 1700 ELO in chess, which technically makes me “someone who loses with dignity against serious players.” Enough to understand the question, not enough to answer it without measuring. So I designed an experiment.
The architecture, or how to build something in 3 days when you have 7
The week lasted, in practice, three days. The rest was actual vacation, which also matters even if this post isn’t about that. So the margin for error was zero.
The system has three layers:
Chess game
↓
Stockfish 17 (depth 18-22, multi-PV 2-3)
↓ [tactical analysis per move]
Qwen3-14B with LoRA fine-tune
↓ [expert verbalization]
PGN comments in natural language
Stockfish does the heavy, deterministic analytical work. The LLM does the verbalization. What I wanted to measure was exactly where one ends and the other begins.
The student model was Qwen3-14B. The training framework, LLaMA-Factory with DeepSpeed ZeRO-3. The final output: a Q5_K_M GGUF of ~10.5 GB that runs on a 16 GB RTX 5060 Ti. From H200 to laptop in an rsync.
The data: 27,414 examples and none synthetic
Before training anything, you need data. This part seems boring but it’s where the most is at stake.
The dataset consists of chess games with comments written by real humans —masters, annotators, commentators— extracted from public sources. For each move: the PGN up to that point, Stockfish analysis converted to tags, and the human comment as the target output.
27,414 examples. Splits: 24,672 for training, 1,370 for evaluation, 1,372 for testing.
The important decision was not to generate a single comment with an LLM. The model would learn from the judgment of a human master, not from another model. The temptation to scale to 200K examples by generating with GPT-4 is real, and I rejected it. If the dataset has synthetic contamination, what the model learns to imitate is another model, not an expert. And we already have enough models imitating other models in the world.
The Stockfish tags: the prompt scaffolding
Each move in the prompt carries specific tactical markers:
25...Nd5 [%best Kd7] [%spread 1.50] [%hang Nd5(White)]
[%best Kd7]— the best alternative according to the engine[%spread 1.50]— the evaluation changed by ≥0.5 points, critical position[%hang Nd5(White)]— there’s a hanging white piece, undefended
These tags are explicit hints. Later I’ll talk about what happens when we remove them. That’s the most interesting part of the experiment.
The four conditions, or how to design an experiment while packing your suitcase
The experimental design has four main conditions and two ablation variants:
| ID | Name | Description |
|---|---|---|
| A | Base | Qwen3-14B untouched. What does it know from pretraining? |
| B | Base + Prompt | No fine-tuning, with detailed system prompt + full tags |
| C | LoRA nothink | Fine-tuned on human comments, no explicit reasoning |
| D | LoRA thinking | Fine-tuned with human comments + generated reasoning blocks |
| C_notags | Clever Hans C | Condition C without Stockfish tags |
| D_notags | Clever Hans D | Condition D without Stockfish tags |
Conditions C and D are the actual fine-tuning. The difference between them is a single line in the YAML config:
# Condition C: template: qwen3_nothink # The model learns directly input → output # Condition D: template: qwen3 # The model learns <think>reasoning</think> → output
One YAML line. About 16 hours of training on the H200s. Radically different results when you remove the hints, but that comes later.
Training, or the zen experience of staring at a screen for 16 hours
Launching training on the H200 server is done with a command. The infrastructure was already in place: Docker, LLaMA-Factory, DeepSpeed ZeRO-3, tmux. What comes next is waiting.
tmux attach -t lora tail -f /root/lora_train.log
There’s something hypnotic and slightly absurd about watching thousands of training steps scroll by while you’re on vacation. The loss was dropping as expected. Every 200 steps, a checkpoint. Every checkpoint, an evaluation. Everything normal.
Condition C: train_loss = 0.2817, eval_loss = 0.2980. Clean convergence. Condition D: train_loss = 0.3126, eval_loss = 0.3022. Clean as well.
Good numbers. The model was learning something. The question was what.
The silent model
This is where the experiment gets interesting, in the sense of “interesting” that doctors use when looking at an X-ray with a serious face.
Condition C trained perfectly. It learned the structure, the vocabulary, the tone of an expert commentator. Zero move hallucinations —it didn’t invent a single nonexistent move across 200 evaluation examples, which was neither trivial nor guaranteed.
But there was a problem:
It comments on 5.2% of blunders and mistakes.
For those who don’t play chess: a blunder is when you make a move so bad that the engine assigns a loss of more than 2 evaluation points. It’s the type of move a human commentator always points out. Always. It’s literally their job.
Condition C almost never does it.
Compare with Condition B, which is just a good system prompt without fine-tuning:
| Metric | A (Base) | B (Base+Prompt) | C (LoRA) |
|---|---|---|---|
| Blunder/mistake coverage | 15.9% | 97.8% | 5.2% |
| Eval direction accuracy | 98.6% | 96.9% | 99.5% |
| Variety (no repetition) | 82.4% | 92.2% | 99.5% |
| Causal density (why_ratio) | 15.5% | 11.3% | 1.3% |
| Words per comment | 21.1 | 25.0 | 11.0 |
B, without training anything at all, covers 97.8% of serious errors. C, trained for 16 hours on top-tier hardware, covers 5.2%.
My first honest reaction was: “did I break something?” The second, after reviewing the pipeline three times: no, I didn’t break anything. What happened is more subtle.
The model learned the human master’s selectivity from the dataset too well. In real data, human commentators don’t point out every error in every game. They flag the most interesting, the most instructive ones. C internalized that selectivity and took it to the extreme: it decided that almost no error deserves mention. Technically consistent with the dataset. Practically useless as a commentator.
It learned when to speak and how to sound expert. But if you ask it why that move was a mistake, it responds confidently in 1.3% of cases. The rest of the time, eloquent silence.
The unexpected takeaway about B
Condition B deserves its own paragraph because it’s uncomfortable for the fine-tuning narrative.
B is Qwen3-14B with a detailed system prompt and full Stockfish tags. Without modifying the model. Without touching the weights. Forty minutes of prompt design work, zero GPU hours.
And it covers 97.8% of serious errors.
The lesson I take, and I’ll repeat to anyone who asks me about fine-tuning: always measure your prompt engineering baseline before training. Fine-tuning doesn’t win in every dimension, and in this case it loses spectacularly in the most obvious one. Condition C wins in accuracy, variety, and absence of noise. But if what you want is a commentator that flags serious errors, B gives you 97.8% for free.
The thinking block trick, or how not to fall into the obvious again
Condition D required generating reasoning blocks to add to the training dataset. The idea: if the model learns the process of reasoning in addition to the output, does it internalize real understanding?
The obvious approach is to give the teacher model (Qwen3-32B with thinking enabled) the same prompt it would use in production and ask it to reason:
Input: PGN + Stockfish tags Generated output: "The position has [%hang Nd5(White)]. There is also [%spread 1.50]. The move is a blunder because..."
This is not reasoning. It’s a checklist disguised as analysis. The model reads [%hang Nd5] and writes “there’s a hanging piece.” It reads [%spread 1.50] and writes “it’s a critical position.” It’s reformatting the input into prose. Exactly the problem we’re trying to measure, but now as part of the training process.
The solution was hindsight rationale: giving the teacher both the problem and the already-solved answer.
Input to teacher: PGN + tags + gold human comment (the already-known answer) Teacher generates: <think> real positional analysis </think> We use: teacher's <think> + original HUMAN comment
By giving it the answer upfront, the teacher has to answer a different question: not what to say, but why a master would say this in this position. The result was real positional analysis —variant calculation, threat evaluation, structural understanding— instead of checklists.
The quantifiable difference:
| Version | Avg length | Quality |
|---|---|---|
| v1 (standard prompt) | ~2,000 chars | Paraphrased tag checklists |
| v2 (hindsight rationale) | ~4,000–6,000 chars | Real positional analysis |
Generating 27,414 thinking blocks at that speed took about 36 more hours on the H200s, running four vLLM servers in parallel with concurrency 3, at ~0.21 examples/second. The process: 4 GPUs × concurrency 3 = 12 parallel requests. The day I saw that number I realized that without the H200s this would have taken weeks.
The finding that makes the experiment worthwhile
Condition D with full tags looks almost identical to C. If you go by the standard metrics:
- D covers 3.4% of blunders. C covers 5.2%. Both are basically mute.
- why_ratio goes from 1.3% to 4.9%. It improves, but not spectacularly.
The real difference appears when you run the Clever Hans test.
Clever Hans was a German horse that in the early 20th century “knew” how to do math: you’d ask him what 3×4 is and he’d stomp the ground twelve times. He was a phenomenon. Until a psychologist named Oskar Pfungst isolated the trainer from the equation and the horse stopped working. Hans wasn’t calculating anything. He was reading the trainer’s involuntary micro-expressions that relaxed when he reached the correct number.
The question for our models is the same: are they “reading” the Stockfish tags instead of understanding chess? If we remove the tags, do they fail like Hans without his trainer?
We removed all tags from the input. Only the PGN. No [%hang], no [%spread], no [%best]. And we evaluated:
| Condition | Blunder coverage | Causal reasoning |
|---|---|---|
| C (with tags) | 5.2% | 1.3% |
| C_notags | ~0% | 15.4% |
| D (with tags) | 3.4% | 4.9% |
| D_notags | 66.7% | 3.6% |
C without tags: collapses. Hans confirmed. Tag dependency = −1.00 across all metrics.
D without tags: serious error coverage rises from 3.4% to 66.7%.
The model that learned to reason during training, when we remove the external hints, comments on serious errors almost twenty times more than when it has them. D’s causal dependency score is +0.26 without tags, compared to −1.00 for C.
The interpretation: when tags are present, D uses them as scaffolding and becomes terse. When tags disappear, it activates the reasoning it internalized during thinking training. The competence was there, latent, waiting until no crutches were available.
The full numbers, for those who like numbers
Evaluation over 200 examples per condition, 1,200 total, 14 metrics:
| Metric | A | B | C | D | C_notags | D_notags |
|---|---|---|---|---|---|---|
| Valid PGN | 100% | 100% | 100% | 100% | 100% | 100% |
| Blunder coverage | 15.9% | 97.8% | 5.2% | 3.4% | — | 66.7% |
| Eval direction accuracy | 98.6% | 96.9% | 99.5% | 98.9% | 100% | 100% |
| No repetition | 82.4% | 92.2% | 99.5% | 99.4% | 100% | 99.9% |
| No hallucinations | 100% | 100% | 100% | 100% | — | 100% |
| Causal reasoning | 15.5% | 11.3% | 1.3% | 4.9% | 15.4% | 3.6% |
| Words/comment | 21.1 | 25.0 | 11.0 | 11.9 | 19.3 | 11.5 |
The number I like the most: move hallucinations = 0% across all fine-tuned conditions. The model didn’t invent a single move that didn’t occur in the game. This was not obvious. Fine-tuning on high-quality gold data produces factually reliable models in the domain, and that has practical value regardless of the rest.
What I conclude, with the distance of someone who’s already back from the server
1. Fine-tuning teaches the *what*, not the *why*.
LoRA-C learned format, style, and selectivity almost perfectly. The problem is that causal reasoning dropped from 15.5% (base) to 1.3%. The model knows when to speak and how to sound expert. It doesn’t know why a move is bad unless you explicitly tell it.
2. Prompt engineering remains ridiculously competitive.
Condition B, without a single training step, covers 97.8% of serious errors. Any project that jumps straight to fine-tuning without first measuring what a good prompt can deliver is leaving money (and GPU hours) on the table.
3. Thinking training internalizes reasoning. Partially, but genuinely.
D scores +0.26 causal dependency without tags; C scores −1.00. It’s not a revolution, but it’s a real, measurable delta. Learning the reasoning process leaves a trace in the model even when external hints disappear.
4. Clever Hans confirmed, with nuance.
Both models depend on tags to produce structure and coverage. But D retains independent reasoning capacity. The distinction isn’t binary (understands/doesn’t understand): it’s gradual. Thinking training moves the needle.
5. D’s silence is the finding, not a failure.
The easy narrative would have been “I trained a model and it works well.” The real narrative is more interesting: the model that learned to reason is more useless under normal conditions, but the day you take away its crutches, suddenly someone’s home. That’s what makes the experiment worthwhile.
The lessons I take away, which apply beyond chess
| Area | Lesson |
|---|---|
| Data | Quality > quantity. 27K gold examples > 500K synthetic. The model’s ceiling is set by the dataset. |
| Architecture | Separate data into immutable layers. Stockfish analysis is computed once; prompts are rebuilt in seconds when you change something. |
| Baseline | Measure B before training C. Always. No excuses. |
| Fine-tuning | Teaches format and style well. For causal reasoning, the reasoning has to be in the training data. |
| Hindsight rationale | Giving the answer so the model rationalizes the path works and is generalizable to any domain with quality ground truths. |
| Evaluation | The ablation test (removing hints) is more revealing than any metric with the full input. |
| Infrastructure | Four H200s on vacation = weeks of work in three days. Hardware matters, though it shouldn’t be the excuse not to run the experiment with whatever you have. |
The app in action: Carlsen vs Mamedyarov, Tata Steel 2022
All of this looks good in metrics over 200 examples, but the real litmus test is to feed a concrete game and see what it generates. The app has a web interface: you paste the PGN, click Analyze Game, Stockfish analyzes the 53 positions, and the model generates the comments.
The test game was Carlsen–Mamedyarov, Tata Steel Masters 2022. A technical game: Carlsen wins with the Catalan without serious errors, building a positional advantage over 27 moves before Mamedyarov resigns.
The app: paste PGN, choose level, analyze. Stockfish analysis takes a few seconds; comment generation takes a bit longer.
Stockfish processing positions in real time. The progress bar is therapeutic.
Game summary: what it gets right
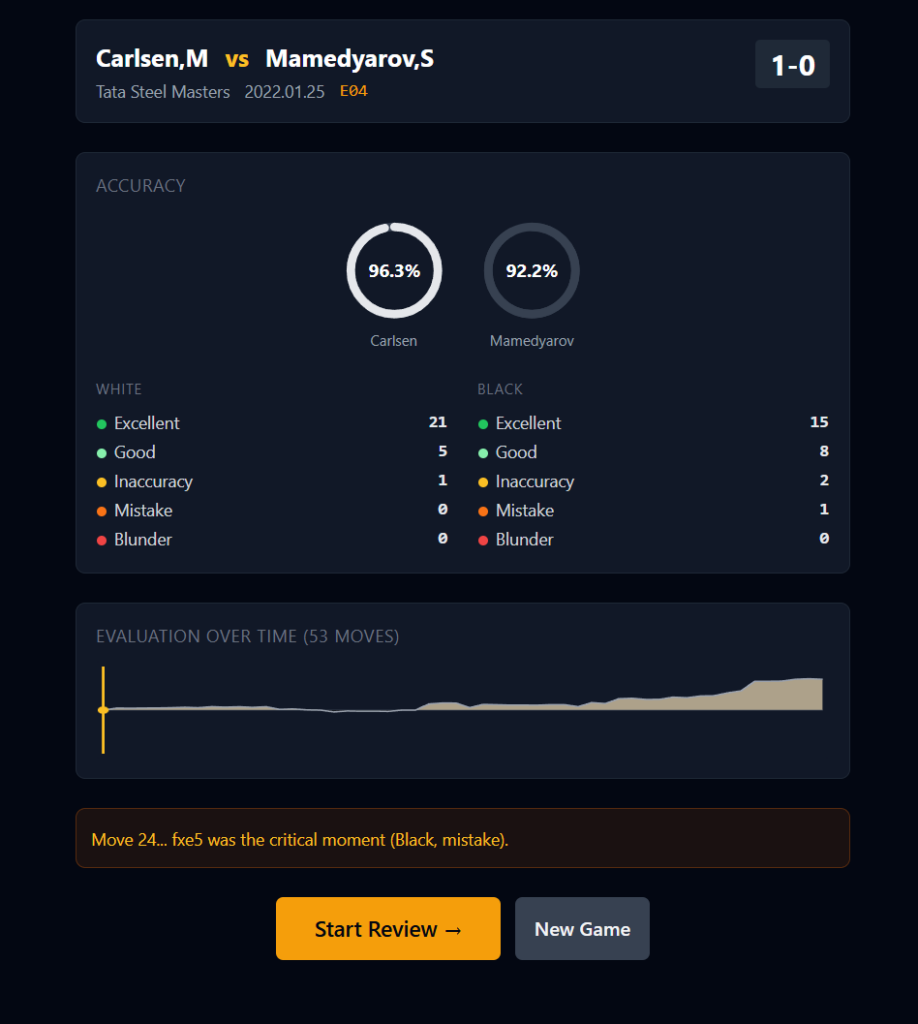
The accuracy summary is solid: Carlsen at 96.3%, Mamedyarov at 92.2%. The identification of the critical moment —“Move 24… fxe5 was the critical moment (Black, mistake)”— is correct. The eval chart shows exactly what happened: equal position until move 20, then a white advantage that gradually grows until resignation. None of this is the model’s invention; it’s well-presented Stockfish analysis.
So far, Condition B with a good prompt would do the same. The question is what happens in the individual comments.
The natural experiment: the same game annotated by a Grandmaster
Here I had a methodological stroke of luck. This exact game —Carlsen–Mamedyarov, round 9 of Tata Steel 2022— is annotated on Chess.com by GM Dejan Bojkov, with quotes from Carlsen himself about what he was thinking during the game. In other words: I have, move by move, what a real human expert writes versus what my model writes about the same positions. There’s no better control for the question posed by this post.
The contrast is not one of nuance. It’s structural. What follows are real examples, verified over the board, from both PGNs.
1. The central theme of the game: the model doesn’t see it.
For Bojkov and for Carlsen, this game has a clear narrative axis: an exchange sacrifice (rook for bishop). On move 14 Black gives up material and on 16.Bxa5 Nc6 17.Bxb6 Qxb6 completes the idea, giving the b6 rook for the bishop in exchange for positional compensation. Carlsen explains it:
“I think the exchange sacrifice was quite expected. It was also his style, one hundred percent.” — Carlsen
“I think he had reasonable compensation.” — Carlsen, on 17…Qxb6
My model, on that same move 17…Qxb6, writes:
“it exchanges the active bishop for the queen… the queen lands on a strong square (b6), where it exerts pressure on the long diagonal and supports White’s kingside attack.”
Two problems. First: it never mentions that this is an exchange sacrifice —the theme that gives structure to the entire game according to the world champion—. Second, and worse: it says the black queen supports White’s attack. It’s a piece from one side working for the other. It’s not a debatable nuance: it’s a sentence with analytical structure and impossible semantics.
2. The invented geometry.
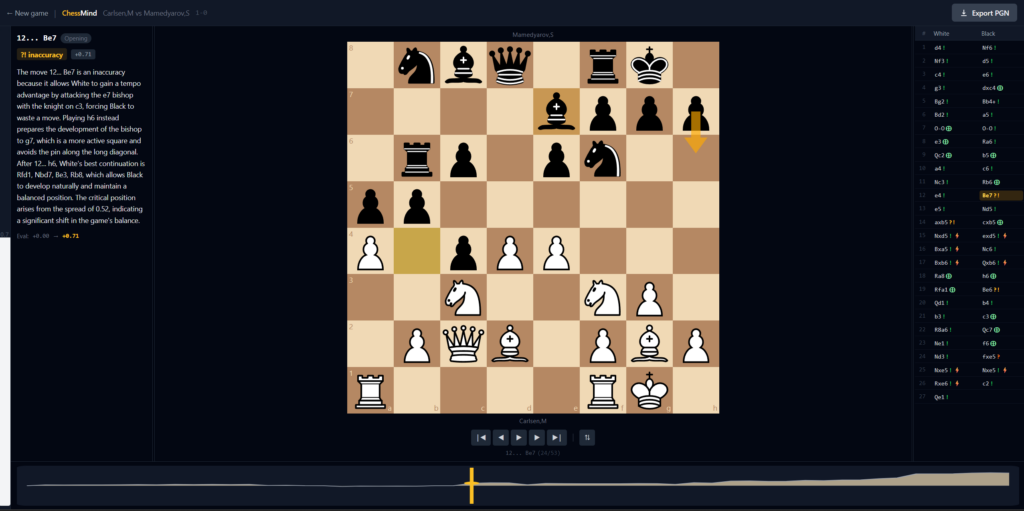
Bojkov on 12…Be7 sticks to what’s correct: “And Mamedyarov offers, in return, the pawn back.” One sentence, exact. My model, on the same move:
“it allows White to gain a tempo advantage by attacking the e7 bishop with the knight on c3.”
A knight on c3 attacks a4, b5, d5, e4, b1, d1, e2. It does not attack e7. The tactical relationship it describes doesn’t exist on the board. It sounds like analysis; it isn’t.
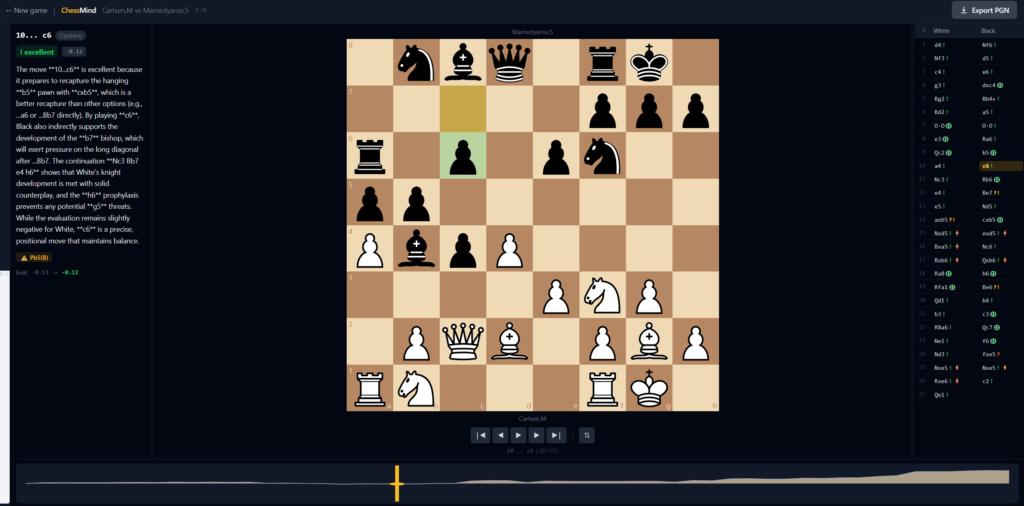
The same thing, inverted, in the opening. Bojkov notes 8…Ra6 as “Sensibly clearing the long diagonal” —the rook clears the long diagonal for the queen’s bishop—. My model, on 10…c6, states that the pawn:
“indirectly supports the development of the b7 bishop, which will exert pressure on the long diagonal after …Bb7.”
The pawn on c6 is on that same diagonal (b7-c6-d5-e4…). It doesn’t support it: it blocks it. The model exactly inverted the positional idea the expert makes explicit.
And on 24.Nd3, where Bojkov writes “Very energetical play!” explaining the maneuver Ne1-d3 (rerouting the knight to block the passed pawn and reactivate the center), my model says the knight “indirectly threatens to play e4”. There’s a white pawn on e5 since move 13. e4 is an impossible move.
3. Where the model gets it right, it’s copying the expert.
This is, to me, the most revealing example of all. On the alternative 19…b4, my model gives the line 20.Rxc8 Rxc8 21.Qf5. Bojkov gives: 20.Rxc8! Rxc8 21.Qf5 Rd8 22.e6 Bf6 23.exf7+ Kf8! 24.Re1.
They match move for move. The model is correct here —because it’s reproducing a line it saw in its training material, not because it calculated it—. And the proof that it didn’t calculate is that, even while copying, it adds its own error: it says Qf5 “invades the 7th rank”. f5 is the fifth rank. When it reproduces, it gets it right; the moment it reasons a millimeter on its own, the geometry breaks.
4. Selectivity: comments on the trivial, silent on the brilliant.
The move Bojkov highlights with admiration —23.Ne1, “A star maneuver! The knight opens the road for the bishop and the white kingside pawns, and it is also ready to block the enemy passer”— my model marks with $1 and doesn’t comment. The most beautiful idea in the game goes unnoticed.
Instead, its scoring contradicts the expert in both directions. It marks 18…h6 as excellent ($1); Bojkov criticizes it: “Played without much thought… this allows White a valuable tempo.” And it marks 24…fxe5 as a blunder ($2) without comment; Bojkov explains it was forced: “there was no way out”, demonstrating with 24...Nxd4 25.Rxe6! Nxe6 26.Bxd5 that the alternative also lost. It rewards an inaccuracy and punishes as a serious error a forced move.
(As a production note: several comments are also cut off mid-sentence —the one for 25...Nxe5 literally ends with “…If Black”—, a symptom of token limit truncation. But that’s a pipeline problem, not a comprehension one.)
What the game proves that metrics only suggest
Placed side by side, the two PGNs summarize the experiment better than the 14-metric table:
- The evaluative direction holds. The model never calls a brilliant move a mistake. The 99.5% eval_direction_match is real: it never contradicts Stockfish’s sign.
- The tone is indistinguishable from an expert’s. Read it without a board in front of you and it sounds like Bojkov. Lines, piece names, concrete squares, positional vocabulary.
- But the geometric and strategic truth falls apart. The expert sees the exchange sacrifice that defines the game; the model describes it backwards. The expert explains the knight maneuver; the model proposes an impossible move. The expert clears a diagonal; the model thinks the pawn that blocks it supports it. Where the model is correct, it’s paraphrasing the expert, and gives itself away with a rank error while copying.
The model does exactly what the experiment predicted: it paraphrases with convincing expert tone, and the moment it has to sustain a claim about the actual geometry of the board, it fails with a frequency that no club player would overlook. It’s not a bug. It’s the empirical answer to the question in the title.
What this experiment demonstrates (and what it doesn’t)
Here I stop reporting and start interpreting, because the contrast with Bojkov forces clarity about what these data actually prove.
When Bojkov writes “the knight clears the way for the bishop”, he’s reading an internal structure: an 8×8 board, pieces with movement rules that are hard constraints, spatial relationships that exist before words. The words come after, as a description of something already represented. Stockfish has that same structure, in silicon. The bishop can’t jump because the representation doesn’t allow it.
This model —Qwen3-14B fine-tuned with LoRA on 27K examples— has not developed a reliable internal representation of that geometry. When it writes “the knight on c3 attacks e7”, it’s not consulting any board and checking that the statement is false: it’s producing the most plausible text string given the context. Nothing in the training process forced it to represent geometry as a constraint it must respect, and the data confirms it: the geometric errors are not occasional but systematic. It can imitate the surface of analysis —the vocabulary, the rhythm, the shape of reasoning— with astonishing fidelity, but the truth of the board is not internally guaranteed.
This does not mean that no LLM can represent chess geometry. It’s a much narrower claim: this specific approach —Stockfish verbalization + LoRA fine-tune on Qwen3-14B— doesn’t achieve it. In recent years we’ve seen models develop surprising internal representations of syntax, arithmetic, spatial navigation, games, and logical structures. The open scientific question is whether those representations can reach the precision that a domain as rigid as chess demands. This experiment doesn’t answer that question —it simply shows that this path doesn’t get there.
That also explains why D_notags moves the needle but doesn’t solve it: thinking training pushes some structure into the weights, but it’s still language approximating geometry without an explicit mechanism guaranteeing spatial correctness. The ceiling of this approach is set by the absence of an internal board representation, not necessarily by the transformer architecture in the abstract.
One promising direction —among others— would be an architecture that carries the conceptual structure of chess inside it —a board state, a legal move generator, the relationships between pieces— as part of the model, not as an external tool the model paraphrases (that’s precisely the Clever Hans trap I measure in this experiment: reading Stockfish is not understanding). A symbolic and geometric component that the model is forced to consult, and by which it is constrained, so that stating the impossible becomes impossible. The language layer would verbalize; the structured layer would guarantee truth. Neuro-symbolic approaches, world models, reasoning over a latent board state rather than over tokens. In essence, giving the model what Stockfish and Bojkov already have: a faithful representation of the board, but internalized, not consulted externally.
I’m fairly certain that’s how you’d achieve far more robust results. I’m also fairly certain that’s not a weekend fine-tune: it’s a months-long research line, an entirely different project, and not something I’m going to take on with the time I have. I’m writing it here because it’s the honest conclusion of the experiment, even though it far exceeds what this vacation was meant to accomplish.
The architecture is generalizable
The underlying pattern —expert engine that analyzes + LLM that verbalizes + hindsight rationale for reasoning— applies directly to any domain where a specialized system produces structured analysis that then needs to be communicated:
- Sports analysis: the statistics system detects the key moment, the LLM narrates it for the fan
- Trading: algorithmic technical signals + LLM that explains the decision in natural language
- Code review: linter/profiler/static analysis + LLM that explains the problem and proposes the solution
- Medicine: specialized diagnostic tool + LLM that writes the clinical report
And in all those cases, the underlying research question is exactly the same: how much does the model understand and how much is it paraphrasing the tool?
The Clever Hans test —removing external hints and measuring what remains— is how you answer it.
Epilogue
The central question remains technically open. “Can an LLM understand chess?” doesn’t have a binary answer. What we have is something more nuanced: an untrained model paraphrases the engine perfectly with the right instructions. A fine-tuned model learns the style but loses the explanation. A fine-tuned model with explicit reasoning internalizes something real, but it’s hard to see until you remove the crutches.
The answer is not yes or no. It’s +0.26 versus −1.00 on a tag dependency index. Small, real, measurable, and more honest than any other conclusion I could have drawn.
That’s why doing the experiment matters, instead of just having opinions.
Stack: Qwen3-14B · LoRA · LLaMA-Factory · DeepSpeed ZeRO-3 · Stockfish 17 · vLLM · llama.cpp