Hay una frase que todo ingeniero de software con cierta trayectoria reconoce inmediatamente como señal de alerta. No es «necesito que lo tengas para mañana», ni «¿puedes echarle un vistazo rápido a esto?». Es mucho más sutil y peligrosa:
«Oye, tengo unos servidores libres esta semana, ¿los necesitas para algo?»
Mi jefe lo dijo con la despreocupación de quien te ofrece una galleta. Lo que me estaba ofreciendo, en realidad, eran cuatro GPUs H200, 141 GB de VRAM cada una, 564 GB en total. Hardware que en el mercado spot te costaría fácilmente 50€/hora si tienes suerte con el proveedor.
Disponibles durante una semana. Mis vacaciones.
El problema que no tenía antes de que me lo prestaran
El experimento nació en ese momento, como todos los proyectos que valen la pena: por oportunidad y por una pregunta que te molestaba desde hacía tiempo.
La pregunta era esta: ¿puede un LLM entender ajedrez de verdad, o solo verbaliza lo que el motor le dice?
La diferencia es importante y no es obvia. Un sistema habitual de comentario automático de partidas funciona así: Stockfish analiza la posición, encuentra que la jugada fue un error, calcula la mejor alternativa, y el LLM convierte eso en una frase con palabras como «en esta posición crítica, las blancas debieron preferir Nf6, manteniendo la presión sobre el peón clavado en e5». Suena exactamente como lo diría un maestro. Pero, ¿el modelo entiende eso, o está reformateando el output de Stockfish en lenguaje natural?
Es la diferencia entre un periodista deportivo que entiende fútbol y uno que lee en voz alta el acta del partido.
Tengo unos 1700 de ELO en ajedrez, lo que técnicamente me hace «alguien que pierde con dignidad contra gente seria». Suficiente para entender la pregunta, insuficiente para resolverla sin medir. Así que diseñé un experimento.
La arquitectura, o cómo construir algo en 3 días cuando tienes 7
La semana duró, en la práctica, tres días. El resto fueron vacaciones reales, que también son importantes aunque este post no vaya de eso. Así que el margen de error era cero.
El sistema tiene tres capas:
Partida de ajedrez
↓
Stockfish 17 (depth 18-22, multi-PV 2-3)
↓ [análisis táctico por jugada]
Qwen3-14B con LoRA fine-tune
↓ [verbalización experta]
Comentarios PGN en lenguaje natural
Stockfish hace el trabajo analítico pesado y determinista. El LLM hace la verbalización. Lo que me interesaba medir es exactamente dónde termina uno y empieza el otro.
El modelo estudiante era Qwen3-14B. El framework de entrenamiento, LLaMA-Factory con DeepSpeed ZeRO-3. El output final: un GGUF Q5_K_M de ~10.5 GB que corre en una RTX 5060 Ti de 16 GB. De H200 a laptop en un rsync.
Los datos: 27.414 ejemplos y ninguno sintético
Antes de entrenar nada hay que tener datos. Esta parte parece aburrida pero es donde más se juega.
El dataset son partidas de ajedrez con comentarios escritos por humanos reales —maestros, anotadores, commentaristas— extraídos de fuentes públicas. Por cada jugada: el PGN hasta ese momento, el análisis de Stockfish convertido en tags, y el comentario del humano como output objetivo.
27.414 ejemplos. Splits: 24.672 para entrenamiento, 1.370 para evaluación, 1.372 para test.
La decisión importante fue no generar ni un solo comentario con un LLM. El modelo iba a aprender del criterio de un maestro humano, no de otro modelo. La tentación de escalar a 200K ejemplos generando con GPT-4 es real y la rechacé. Si el dataset tiene contaminación sintética, lo que el modelo aprende a imitar es a otro modelo, no a un experto. Y ya tenemos suficientes modelos imitando a otros modelos en el mundo.
Los tags de Stockfish: el andamiaje del prompt
Cada jugada en el prompt lleva marcadores tácticos específicos:
25...Nd5 [%best Kd7] [%spread 1.50] [%hang Nd5(White)]
[%best Kd7]— la mejor alternativa según el motor[%spread 1.50]— la evaluación cambió ≥0.5 puntos, posición crítica[%hang Nd5(White)]— hay una pieza blanca colgada, indefensa
Estos tags son pistas explícitas. Más adelante hablaré de qué pasa cuando las quitamos. Es la parte más interesante del experimento.
Las cuatro condiciones, o cómo diseñar un experimento mientras haces la maleta
El diseño experimental tiene cuatro condiciones principales y dos variantes de ablación:
| ID | Nombre | Descripción |
|---|---|---|
| A | Base | Qwen3-14B sin tocar. ¿Qué sabe por preentrenamiento? |
| B | Base + Prompt | Sin fine-tuning, con system prompt detallado + tags completos |
| C | LoRA nothink | Fine-tuned sobre comentarios humanos, sin razonamiento explícito |
| D | LoRA thinking | Fine-tuned con comentarios humanos + bloques de razonamiento generados |
| C_notags | Clever Hans C | Condición C sin los tags de Stockfish |
| D_notags | Clever Hans D | Condición D sin los tags de Stockfish |
Las condiciones C y D son el fine-tuning real. La diferencia entre ellas es una sola línea en el YAML de configuración:
# Condición C: template: qwen3_nothink # El modelo aprende directamente input → output # Condición D: template: qwen3 # El modelo aprende <think>razonamiento</think> → output
Una línea de YAML. Unos 16 horas de entrenamiento en las H200. Resultados radicalmente distintos cuando quitas las pistas, pero eso va después.
El entrenamiento, o la experiencia zen de mirar una pantalla durante 16 horas
Lanzar el entrenamiento en el servidor H200 se hace con un comando. La infraestructura ya estaba: Docker, LLaMA-Factory, DeepSpeed ZeRO-3, tmux. Lo que viene después es esperar.
tmux attach -t lora tail -f /root/lora_train.log
Hay algo hipnótico y ligeramente absurdo en ver pasar miles de steps de entrenamiento mientras estás en vacaciones. La loss bajaba como debía. Cada 200 steps, un checkpoint. Cada checkpoint, una evaluación. Todo normal.
Condición C: train_loss = 0.2817, eval_loss = 0.2980. Convergencia limpia. Condición D: train_loss = 0.3126, eval_loss = 0.3022. También limpia.
Números buenos. El modelo estaba aprendiendo algo. La pregunta era qué.
El modelo mudo
Aquí es donde el experimento se pone interesante, en el sentido de «interesante» que usan los médicos cuando están mirando una radiografía con cara seria.
Condición C entrenó perfectamente. Aprendió la estructura, el vocabulario, el tono de un comentarista experto. Cero alucinaciones de jugadas —no inventó ni una sola jugada inexistente en 200 ejemplos de evaluación, lo que no era trivial ni garantizado.
Pero había un problema:
Comenta el 5.2% de los blunders y mistakes.
Para los que no juegan al ajedrez: un blunder es cuando haces una jugada tan mala que el motor te asigna una pérdida de más de 2 puntos de evaluación. Es el tipo de jugada que un comentarista humano siempre señala. Siempre. Es literalmente su trabajo.
Condición C no lo hace casi nunca.
Comparad con Condición B, que es solo un buen system prompt sin fine-tuning:
| Métrica | A (Base) | B (Base+Prompt) | C (LoRA) |
|---|---|---|---|
| Cobertura de blunders/mistakes | 15.9% | 97.8% | 5.2% |
| Precisión de dirección eval | 98.6% | 96.9% | 99.5% |
| Variedad (sin repetición) | 82.4% | 92.2% | 99.5% |
| Densidad causal (why_ratio) | 15.5% | 11.3% | 1.3% |
| Palabras por comentario | 21.1 | 25.0 | 11.0 |
B, sin entrenar absolutamente nada, cubre el 97.8% de los errores graves. C, entrenado durante 16 horas en hardware de primer nivel, cubre el 5.2%.
La primera reacción honesta fue: «¿rompí algo?». La segunda, después de revisar el pipeline tres veces: no, no rompí nada. Lo que ocurrió es más sutil.
El modelo aprendió demasiado bien la selectividad del maestro humano del dataset. En los datos reales, los comentaristas humanos no señalan todos los errores de todas las partidas. Comienzan los más interesantes, los más instructivos. C internalizó esa selectividad y la llevó al extremo: decidió que casi ningún error merece mención. Técnicamente coherente con el dataset. Prácticamente inútil como commentarista.
Aprendió cuándo hablar y cómo sonar experto. Pero si le preguntas por qué esa jugada fue un error, responde con confianza en el 1.3% de los casos. El resto del tiempo, silencio elocuente.
El dato que no esperaba sobre B
La Condición B merece un párrafo propio porque es incómoda para la narrativa del fine-tuning.
B es Qwen3-14B con un system prompt detallado y los tags de Stockfish completos. Sin modificar el modelo. Sin tocar los pesos. Cuarenta minutos de trabajo de diseño de prompt, cero horas de GPU.
Y cubre el 97.8% de los errores graves.
La lección que me llevo, y que voy a repetir a cualquiera que me pregunte sobre fine-tuning: mide siempre tu baseline de prompt engineering antes de entrenar. El fine-tuning no gana en todas las dimensiones, y en este caso pierde estrepitosamente en la más obvia. Condición C gana en precisión, variedad y ausencia de ruido. Pero si lo que quieres es un comentarista que señale los errores graves, B te da el 97.8% gratis.
El truco de los thinking blocks, o cómo no volver a caer en lo obvio
La Condición D requería generar bloques de razonamiento para añadir al dataset de entrenamiento. La idea: si el modelo aprende el proceso de razonamiento además del output, ¿internaliza comprensión real?
El enfoque obvio es darle al modelo teacher (Qwen3-32B con thinking activado) el mismo prompt que usa en producción y pedirle que razone:
Input: PGN + tags de Stockfish Output generado: "The position has [%hang Nd5(White)]. There is also [%spread 1.50]. The move is a blunder because..."
Esto no es razonamiento. Es una lista de verificación disfrazada de análisis. El modelo lee [%hang Nd5] y escribe «hay una pieza colgada». Lee [%spread 1.50] y escribe «es una posición crítica». Está reformateando el input en prosa. Exactamente el problema que intentamos medir, pero ahora como parte del proceso de entrenamiento.
La solución fue hindsight rationale: darle al teacher tanto el problema como la respuesta ya resuelta.
Input al teacher: PGN + tags + comentario humano gold (la respuesta ya conocida) Teacher genera: <think> análisis posicional real </think> Usamos: <think> del teacher + comentario HUMANO original
Al darle la respuesta de antemano, el teacher tiene que responder a una pregunta diferente: no qué decir, sino por qué un maestro diría esto en esta posición. El resultado fue análisis posicional real —cálculo de variantes, evaluación de amenazas, comprensión estructural— en lugar de checklists.
La diferencia cuantificable:
| Versión | Longitud media | Calidad |
|---|---|---|
| v1 (prompt estándar) | ~2.000 caracteres | Listas de tags parafraseados |
| v2 (hindsight rationale) | ~4.000–6.000 caracteres | Análisis posicional real |
Generar 27.414 thinking blocks a esa velocidad tardó unas 36 horas más en las H200, corriendo cuatro servidores vLLM en paralelo con concurrencia 3, a ~0.21 ejemplos/segundo. El proceso: 4 GPUs × concurrencia 3 = 12 requests paralelos. El día que vi ese número caí en la cuenta de que sin las H200 esto habría tardado semanas.
El hallazgo que hace que el experimento valga la pena
Condición D con los tags completos parece casi idéntica a C. Si te quedas con las métricas estándar:
- D cubre el 3.4% de blunders. C cubre el 5.2%. Ambos son básicamente mudos.
- why_ratio sube de 1.3% a 4.9%. Mejora, pero no espectacular.
La diferencia real aparece cuando haces el test Clever Hans.
Clever Hans era un caballo alemán que a principios del siglo XX «sabía» hacer matemáticas: le preguntaban cuánto es 3×4 y golpeaba el suelo doce veces. Era un fenómeno. Hasta que un psicólogo llamado Oskar Pfungst aisló al entrenador del ecuación y el caballo dejó de funcionar. Hans no calculaba nada. Leía las microexpresiones involuntarias del entrenador que se relajaba cuando llegaba al número correcto.
La pregunta para nuestros modelos es la misma: ¿están «leyendo» los tags de Stockfish en lugar de entender el ajedrez? Si quitamos los tags, ¿fallan como Hans sin su entrenador?
Quitamos todos los tags del input. Solo el PGN. Sin [%hang], sin [%spread], sin [%best]. Y evaluamos:
| Condición | Cobertura blunders | Razonamiento causal |
|---|---|---|
| C (con tags) | 5.2% | 1.3% |
| C_notags | ~0% | 15.4% |
| D (con tags) | 3.4% | 4.9% |
| D_notags | 66.7% | 3.6% |
C sin tags: colapsa. Hans confirmado. Dependencia de tags = −1.00 en todas las métricas.
D sin tags: la cobertura de errores graves sube de 3.4% a 66.7%.
El modelo que aprendió a razonar durante el entrenamiento, cuando le quitamos las pistas externas, comenta casi veinte veces más los errores graves que cuando las tiene. El índice de dependencia causal de D es +0.26 sin tags, frente a −1.00 de C.
La interpretación: cuando los tags están presentes, D los usa como andamiaje y se vuelve parco. Cuando los tags desaparecen, activa el razonamiento que internalizó durante el training con thinking. La competencia estaba ahí, latente, esperando a que no hubiera muletas disponibles.
Los números completos, para los que les gustan los números
Evaluación sobre 200 ejemplos por condición, 1.200 en total, 14 métricas:
| Métrica | A | B | C | D | C_notags | D_notags |
|---|---|---|---|---|---|---|
| PGN válido | 100% | 100% | 100% | 100% | 100% | 100% |
| Cobertura blunders | 15.9% | 97.8% | 5.2% | 3.4% | — | 66.7% |
| Precisión dirección eval | 98.6% | 96.9% | 99.5% | 98.9% | 100% | 100% |
| Sin repeticiones | 82.4% | 92.2% | 99.5% | 99.4% | 100% | 99.9% |
| Sin alucinaciones | 100% | 100% | 100% | 100% | — | 100% |
| Razonamiento causal | 15.5% | 11.3% | 1.3% | 4.9% | 15.4% | 3.6% |
| Palabras/comentario | 21.1 | 25.0 | 11.0 | 11.9 | 19.3 | 11.5 |
El dato que más me gusta: alucinaciones de jugadas = 0% en todas las condiciones fine-tuned. El modelo no inventó ni una sola jugada que no ocurriera en la partida. Esto no era obvio. El fine-tuning sobre datos gold de alta calidad produce modelos factualmente fiables en el dominio, y eso tiene valor práctico independientemente del resto.
Lo que concluyo, con la distancia de quien ya está de vuelta del servidor
1. El fine-tuning enseña el *qué*, no el *por qué*.
LoRA-C aprendió formato, estilo y selectividad de forma casi perfecta. El problema es que el razonamiento causal cayó de 15.5% (base) a 1.3%. El modelo sabe cuándo hablar y cómo sonar experto. No sabe por qué una jugada es mala salvo que se lo digas explícitamente.
2. El prompt engineering sigue siendo ridículamente competitivo.
Condición B, sin un solo paso de entrenamiento, cubre el 97.8% de los errores graves. Cualquier proyecto que empiece por fine-tuning sin medir primero qué da un buen prompt está dejando dinero (y horas de GPU) sobre la mesa.
3. El thinking training internaliza razonamiento. Parcialmente, pero realmente.
D marca +0.26 de dependencia causal sin tags; C marca −1.00. No es una revolución, pero es un delta real y medible. Aprender el proceso de razonamiento deja huella en el modelo incluso cuando las pistas externas desaparecen.
4. Clever Hans confirmado, con matiz.
Ambos modelos dependen de los tags para producir estructura y cobertura. Pero D retiene capacidad de razonamiento independiente. La distinción no es binaria (entiende/no entiende): es gradual. El thinking training mueve la aguja.
5. El silencio de D es el hallazgo, no un fallo.
La narrativa fácil habría sido «entrené un modelo y funciona bien». La narrativa real es más interesante: el modelo que aprendió a razonar es más inútil en condiciones normales, pero el día que le quitas las muletas, de repente hay alguien en casa. Eso es lo que hace que el experimento valga la pena.
Las lecciones que me llevo, que aplican más allá del ajedrez
| Área | Aprendizaje |
|---|---|
| Datos | Calidad > cantidad. 27K ejemplos gold > 500K sintéticos. El techo del modelo lo pone el dataset. |
| Arquitectura | Separar datos en capas inmutables. El análisis de Stockfish se calcula una vez; los prompts se reconstruyen en segundos cuando cambias algo. |
| Baseline | Mide B antes de entrenar C. Siempre. Sin excusas. |
| Fine-tuning | Enseña formato y estilo bien. Para razonamiento causal, el razonamiento tiene que estar en los datos de training. |
| Hindsight rationale | Dar la respuesta para que el modelo racionalice el camino funciona y es generalizable a cualquier dominio con ground truths de calidad. |
| Evaluación | El test de ablación (quitar las pistas) es más revelador que cualquier métrica con el input completo. |
| Infraestructura | Cuatro H200 en vacaciones = semanas de trabajo en tres días. El hardware importa, aunque no debería ser la excusa para no hacer el experimento con lo que tienes. |
La app funcionando: Carlsen vs Mamedyarov, Tata Steel 2022
Todo esto está muy bien en métricas sobre 200 ejemplos, pero la prueba de fuego real es meter una partida concreta y ver qué genera. La app tiene una interfaz web: pegas el PGN, pulsa Analyze Game, Stockfish analiza las 53 posiciones, y el modelo genera los comentarios.
La partida de prueba fue Carlsen–Mamedyarov del Tata Steel Masters 2022. Una partida técnica: Carlsen gana con la Catalana sin errores graves, construyendo ventaja posicional durante 27 movimientos antes de que Mamedyarov se rinda.
La app: pegar PGN, elegir nivel, analizar. El análisis de Stockfish tarda unos segundos; la generación de comentarios, algo más.
Stockfish procesando posiciones en tiempo real. La barra de progreso es terapéutica.
El resumen de la partida: lo que acierta
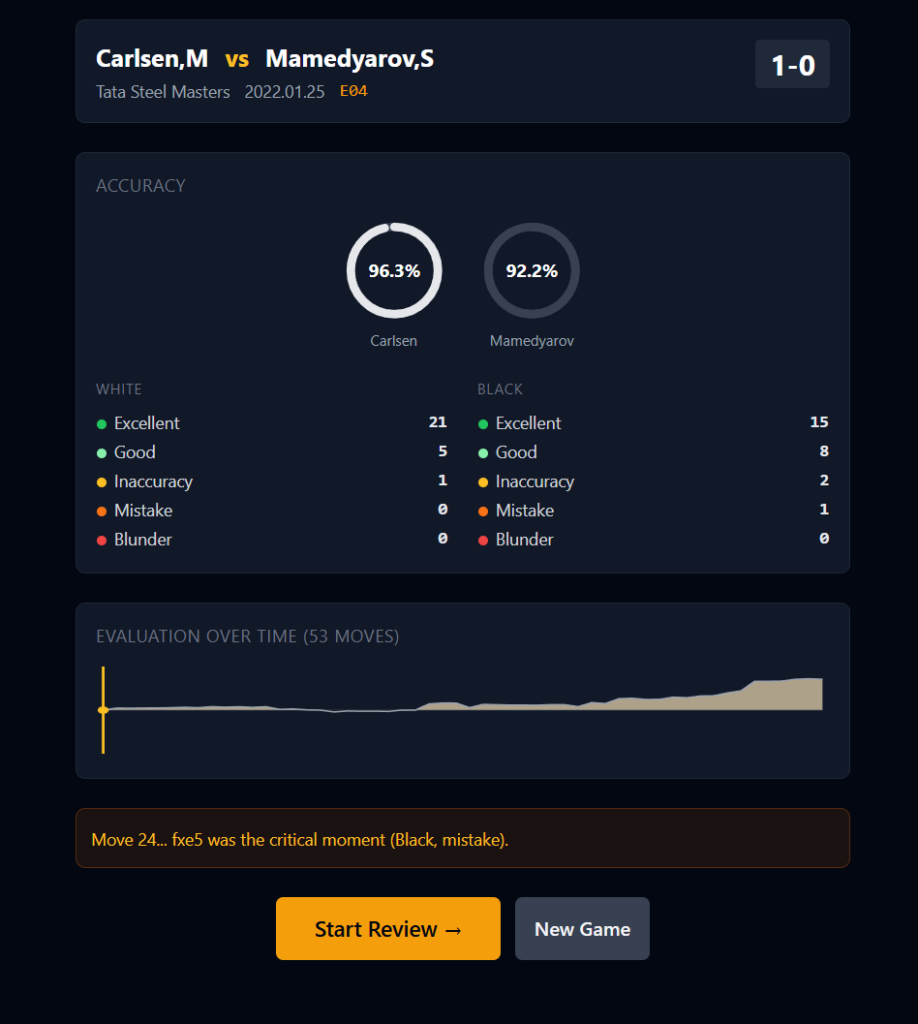
El resumen de accuracy es sólido: Carlsen al 96.3%, Mamedyarov al 92.2%. La identificación del momento crítico —«Move 24… fxe5 was the critical moment (Black, mistake)»— es correcta. El gráfico de evaluación muestra exactamente lo que ocurrió: posición igualada hasta el movimiento 20, luego una ventaja blanca que crece gradualmente hasta el resigno. Nada de esto es invención del modelo; es análisis de Stockfish bien presentado.
Hasta aquí, la Condición B con un buen prompt haría lo mismo. La pregunta es qué pasa en los comentarios individuales.
El experimento natural: la misma partida comentada por un Gran Maestro
Aquí tuve un golpe de suerte metodológico. Esta partida exacta —Carlsen–Mamedyarov, ronda 9 del Tata Steel 2022— está comentada en Chess.com por el GM Dejan Bojkov, con citas del propio Carlsen sobre lo que pensaba durante el juego. Es decir: tengo, jugada a jugada, lo que escribe un experto humano real frente a lo que escribe mi modelo sobre las mismas posiciones. No hay mejor control para la pregunta del post.
El contraste no es de matiz. Es estructural. Lo que sigue son ejemplos reales, verificados sobre el tablero, de los dos PGN.
1. El tema central de la partida: el modelo no lo ve.
Para Bojkov y para Carlsen, esta partida tiene un eje narrativo claro: un sacrificio de calidad (torre por alfil). En la jugada 14 las negras entregan material y en 16.Bxa5 Nc6 17.Bxb6 Qxb6 rematan la idea, dando la torre de b6 por el alfil a cambio de compensación posicional. Carlsen lo explica:
«I think the exchange sacrifice was quite expected. It was also his style, one hundred percent.» — Carlsen
«I think he had reasonable compensation.» — Carlsen, sobre 17…Qxb6
Mi modelo, sobre esa misma jugada 17…Qxb6, escribe:
«it exchanges the active bishop for the queen… the queen lands on a strong square (b6), where it exerts pressure on the long diagonal and supports White’s kingside attack.»
Dos problemas. Primero: nunca menciona que esto es un sacrificio de calidad —el tema que vertebra toda la partida según el campeón del mundo—. Segundo, y peor: dice que la dama negra apoya el ataque de las blancas. Es la pieza de un bando trabajando para el otro. No es un matiz discutible: es una frase con estructura de análisis y semántica imposible.
2. La geometría inventada.
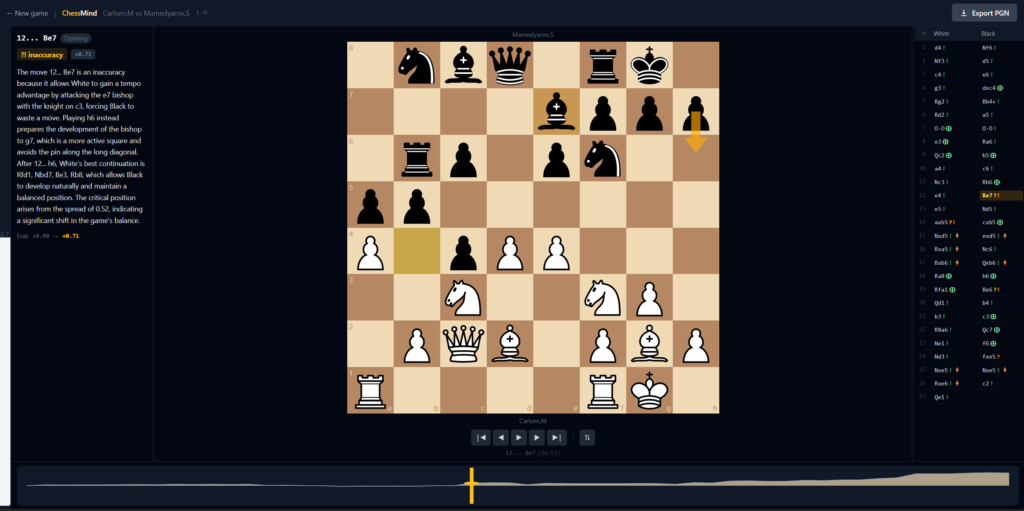
Bojkov sobre 12…Be7 se limita a lo correcto: «And Mamedyarov offers, in return, the pawn back.» Una frase, exacta. Mi modelo, sobre la misma jugada:
«it allows White to gain a tempo advantage by attacking the e7 bishop with the knight on c3.»
Un caballo en c3 ataca a4, b5, d5, e4, b1, d1, e2. No ataca e7. La relación táctica que describe no existe en el tablero. Suena a análisis; no lo es.
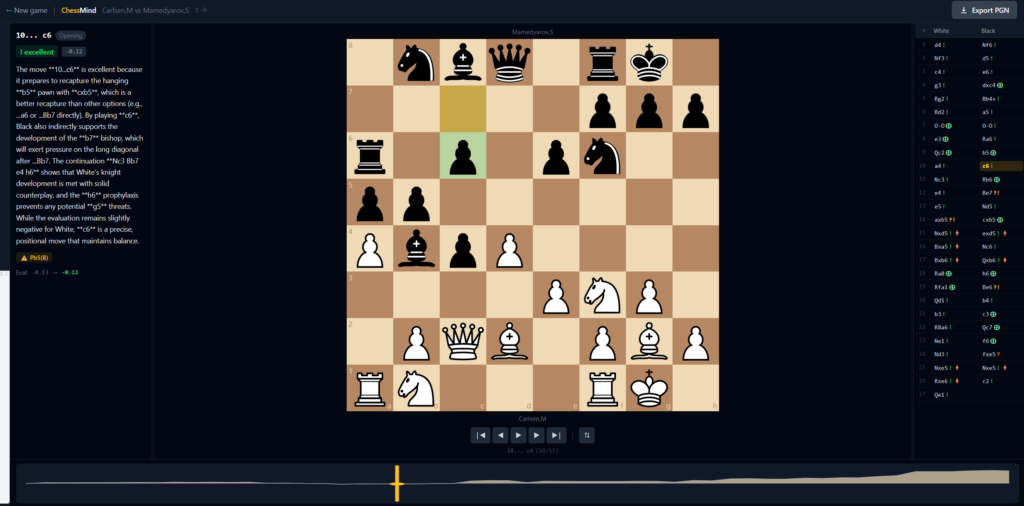
Lo mismo, invertido, en la apertura. Bojkov anota 8…Ra6 como «Sensibly clearing the long diagonal» —la torre despeja la gran diagonal para el alfil de dama—. Mi modelo, sobre 10…c6, afirma que el peón:
«indirectly supports the development of the b7 bishop, which will exert pressure on the long diagonal after …Bb7.»
El peón en c6 está sobre esa misma diagonal (b7-c6-d5-e4…). No la apoya: la bloquea. El modelo invirtió exactamente la idea posicional que el experto explicita.
Y en 24.Nd3, donde Bojkov escribe «Very energetical play!» explicando la maniobra Ne1-d3 (rerutear el caballo para bloquear el peón pasado y reactivar el centro), mi modelo dice que el caballo «indirectly threatens to play e4». Hay un peón blanco en e5 desde la jugada 13. e4 es una jugada imposible.
3. Donde el modelo acierta, está copiando al experto.
Este es, para mí, el ejemplo más revelador de todos. Sobre la alternativa 19…b4, mi modelo da la línea 20.Rxc8 Rxc8 21.Qf5. Bojkov da: 20.Rxc8! Rxc8 21.Qf5 Rd8 22.e6 Bf6 23.exf7+ Kf8! 24.Re1.
Coinciden jugada por jugada. El modelo es correcto aquí —porque está reproduciendo una variante que vio en su material de entrenamiento, no porque la haya calculado—. Y la prueba de que no la calcula es que, incluso copiando, añade un error propio: dice que Qf5 «invades the 7th rank». f5 es la quinta fila. Cuando reproduce, acierta; en cuanto razona un milímetro por su cuenta, la geometría se rompe.
4. La selectividad: comenta lo trivial, calla en lo brillante.
La jugada que Bojkov destaca con admiración —23.Ne1, «A star maneuver! The knight opens the road for the bishop and the white kingside pawns, and it is also ready to block the enemy passer»— mi modelo la marca con un $1 y no la comenta. La idea más bonita de la partida pasa de largo.
En cambio, su puntuación contradice al experto en las dos direcciones. Marca 18…h6 como excelente ($1); Bojkov la critica: «Played without much thought… this allows White a valuable tempo.» Y marca 24…fxe5 como blunder ($2) sin comentario; Bojkov explica que era forzada: «there was no way out», demostrando con 24...Nxd4 25.Rxe6! Nxe6 26.Bxd5 que la alternativa también perdía. Premia una imprecisión y castiga como error grave una jugada obligada.
(Como nota de producción: varios comentarios además se cortan a mitad de frase —el de 25...Nxe5 termina literalmente en «…If Black»—, síntoma de truncamiento por límite de tokens. Pero ese es un problema de pipeline, no de comprensión.)
Lo que la partida demuestra que las métricas solo sugieren
Puestos uno al lado del otro, los dos PGN resumen el experimento mejor que la tabla de 14 métricas:
- La dirección evaluativa se sostiene. El modelo nunca llama brillante a una imprecisión. El 99.5% de eval_direction_match es real: nunca contradice el signo de Stockfish.
- El tono es indistinguible del de un experto. Léelo sin tablero delante y suena a Bojkov. Variantes, nombres de piezas, casillas concretas, vocabulario posicional.
- Pero la verdad geométrica y estratégica se desmorona. El experto ve el sacrificio de calidad que define la partida; el modelo lo describe al revés. El experto explica la maniobra de caballo; el modelo propone una jugada imposible. El experto despeja una diagonal; el modelo cree que el peón que la bloquea la apoya. Donde el modelo es correcto, está parafraseando al experto, y se delata con un error de fila al copiar.
El modelo hace exactamente lo que el experimento predijo: parafrasea con un tono experto convincente, y en cuanto tiene que sostener una afirmación sobre la geometría real del tablero, falla con una frecuencia que ningún jugador federado pasaría por alto. No es un bug de implementación. Es la respuesta empírica a la pregunta del título.
Lo que este experimento demuestra (y lo que no)
Aquí dejo de informar y empiezo a interpretar, porque el contraste con Bojkov obliga a clarificar qué prueban realmente estos datos.
Cuando Bojkov escribe «el caballo despeja el camino para el alfil», está leyendo una estructura interna: un tablero de 8×8, piezas con reglas de movimiento que son restricciones duras, relaciones espaciales que existen antes que las palabras. Las palabras vienen después, como descripción de algo que ya está representado. Stockfish tiene esa misma estructura, en silicio. El alfil no puede saltar porque la representación no lo permite.
Este modelo —Qwen3-14B fine-tuneado con LoRA sobre 27K ejemplos— no ha desarrollado una representación interna fiable de esa geometría. Cuando escribe «el caballo en c3 ataca e7», no está consultando ningún tablero y comprobando que la afirmación es falsa: está produciendo la cadena de texto más plausible dado el contexto. Nada en el proceso de entrenamiento le obligó a representar la geometría como una restricción que deba respetar, y los datos lo confirman: los errores geométricos no son ocasionales, sino sistemáticos. Puede imitar la superficie del análisis —el vocabulario, el ritmo, la forma de un razonamiento— con una fidelidad asombrosa, pero la verdad del tablero no está garantizada internamente.
Esto no significa que ningún LLM pueda representar geometría de ajedrez. Es una afirmación mucho más acotada: este enfoque concreto —verbalización de Stockfish + LoRA fine-tune sobre Qwen3-14B— no lo consigue. En los últimos años hemos visto modelos que desarrollan representaciones internas sorprendentes de sintaxis, aritmética, navegación espacial, juegos y estructuras lógicas. La cuestión científica abierta es si esas representaciones pueden alcanzar la precisión que un dominio tan rígido como el ajedrez exige. Este experimento no responde a esa pregunta —simplemente muestra que este camino no llega.
Eso explica, de paso, por qué D_notags mueve la aguja pero no la resuelve: el thinking training empuja cierta estructura hacia los pesos, pero sigue siendo lenguaje aproximando geometría sin un mecanismo explícito que garantice la corrección espacial. El techo de este enfoque lo pone la ausencia de una representación interna del tablero, no necesariamente la arquitectura transformer en abstracto.
Una dirección prometedora —entre otras posibles— sería una arquitectura que llevara dentro la estructura conceptual del ajedrez —un estado de tablero, un generador de jugadas legales, las relaciones entre piezas— como parte del modelo, no como una herramienta externa que el modelo parafrasea (eso es precisamente la trampa de Clever Hans que mido en este experimento: leer a Stockfish no es entender). Una pieza simbólica y geométrica que el modelo estuviera obligado a consultar, y por la que estuviera restringido, de modo que afirmar lo imposible fuera imposible. La capa de lenguaje verbalizaría; la capa estructurada garantizaría la verdad. Enfoques neuro-simbólicos, modelos del mundo, razonamiento sobre un estado latente del tablero en lugar de sobre tokens. En esencia, darle al modelo lo que Stockfish y Bojkov ya tienen: una representación fiel del tablero, pero interiorizada, no consultada por fuera.
Tengo bastante claro que por ahí se lograrían resultados mucho más robustos. También tengo bastante claro que eso no es un fine-tune de un fin de semana: es una línea de investigación de meses, otro proyecto entero, y no algo que vaya a plantearme con el tiempo que tengo. Lo dejo escrito porque es la conclusión honesta del experimento, aunque exceda con mucho lo que estas vacaciones daban de sí.
La arquitectura es generalizable
El patrón subyacente —motor experto que analiza + LLM que verbaliza + hindsight rationale para razonamiento— aplica directamente a cualquier dominio donde un sistema especializado produce análisis estructurado que después hay que comunicar:
- Análisis deportivo: el sistema de estadísticas detecta el momento clave, el LLM lo narra para el aficionado
- Trading: señales técnicas algorítmicas + LLM que explica la decisión en lenguaje natural
- Code review: linter/profiler/análisis estático + LLM que explica el problema y propone la solución
- Medicina: herramienta de diagnóstico especializada + LLM que redacta el informe clínico
Y en todos esos casos, la pregunta de investigación subyacente es exactamente la misma: ¿cuánto entiende el modelo y cuánto está parafraseando la herramienta?
El test Clever Hans —quitar las pistas externas y medir qué queda— es cómo se responde.
Epílogo
La pregunta central sigue técnicamente abierta. «¿Puede un LLM entender ajedrez?» no tiene una respuesta binaria. Lo que tenemos es algo más matizado: un modelo sin fine-tuning parafrasea el motor perfectamente con las instrucciones correctas. Un modelo fine-tuned aprende el estilo pero pierde la explicación. Un modelo fine-tuned con razonamiento explícito internaliza algo real, pero es difícil de ver hasta que le quitas las muletas.
La respuesta no es sí o no. Es +0.26 frente a −1.00 en un índice de dependencia de tags. Pequeño, real, medible, y más honesto que cualquier otra conclusión que hubiera podido sacar.
Por eso vale la pena hacer el experimento en lugar de solo opinar.
Stack: Qwen3-14B · LoRA · LLaMA-Factory · DeepSpeed ZeRO-3 · Stockfish 17 · vLLM · llama.cpp