La idea empezó de una forma bastante tonta. Llevaba tiempo usando ChatGPT y otras IA conversacionales para practicar inglés, y aunque molaba poder hablar con una máquina, siempre tenía la sensación de que me estaba colando. El reconocimiento de voz funciona por probabilidad: si dices algo mínimamente parecido a lo esperado, la IA te lo da por bueno y sigue la conversación. Nunca sabes si realmente has pronunciado bien o si el modelo te ha entendido porque el contexto se lo ponía fácil.
No es una crítica a esas herramientas —son impresionantes— pero no resuelven lo que yo quería: tener una métrica objetiva de mi pronunciación. Algo que me dijera: «has dicho exactamente esto, y esto es lo parecido que suena a como debería sonar». Y como soy ingeniero de software, se me ocurrió: ¿y si me construyo algo que haga exactamente eso? Sin más pretensión que ver si era capaz, explorar tecnologías que no había usado antes y, de paso, tener una herramienta útil para mí.
Cómo funciona (sin enrollarme)
La idea es simple: escribes un texto, la app lo lee en voz alta con un TTS local, tú lo repites grabándote, y ella compara ambas versiones palabra por palabra. Técnicamente tiene su miga, pero el concepto es directo.
El flujo entero es así:
- Metes un texto en la interfaz (o eliges uno de los que vienen por defecto)
- La app genera el audio de referencia con Kokoro ONNX —un modelo TTS que corre localmente en mi máquina
- Escuchas y grabas tu voz imitando al hablante
- El backend procesa tu grabación con faster-whisper para saber qué has dicho y cuándo
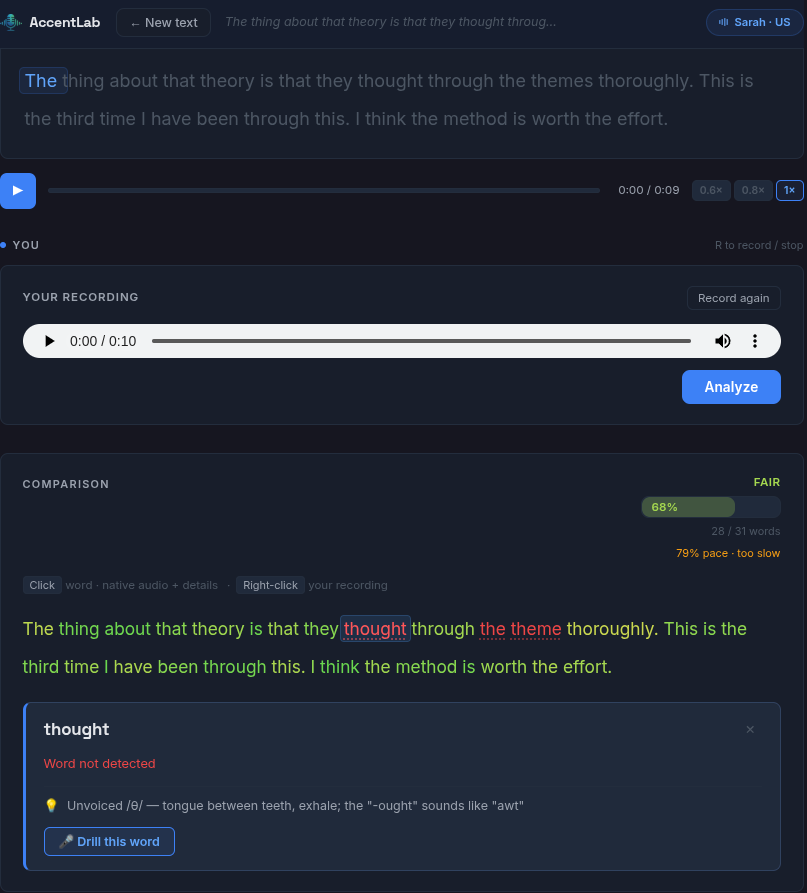
- Compara acústicamente cada una de tus palabras con las del hablante nativo usando MFCC
- Te devuelve una nota con el desglose: qué palabras has clavado y cuáles no
La parte técnica que más me divirtió
Lo que realmente quería explorar con este proyecto era el procesado de audio, algo con lo que había jugado poco. El core del sistema está en la comparación acústica: extraigo los coeficientes MFCC de ambos audios, los normalizo, calculo la similitud coseno entre los vectores resultantes y obtengo una puntuación.
No es ciencia puntera —de hecho es bastante estándar en el mundillo del speech processing— pero verlo funcionar es gratificante. Combinas eso con la probabilidad que devuelve Whisper para cada palabra (lo que yo llamo claridad) y tienes un sistema de evaluación bastante más honesto que una transcripción que te lo da todo por bueno.
Los MFCC miden cómo suena algo. Whisper mide si se entiende. Juntos se compensan. Si una palabra suena parecido pero no es correcta (piensa en ship por sheep), el MFCC te descuenta. Si la has pronunciado con ruido de fondo, Whisper te penaliza. En conjunto el sistema es bastante justo.
Cómo está montado
La arquitectura es el clásico frontend-backend con una capa de modelos local:
- Frontend: React con Vite y CSS Modules. Nada del otro mundo, lo justo para tener una interfaz limpia con un karaoke sincronizado y los controles de grabación.
- Backend: FastAPI. Recibe peticiones de generación de audio y de análisis. Todo corre en el mismo servidor, sin dependencias externas.
- Modelos: Kokoro ONNX para el TTS y faster-whisper para el reconocimiento. Ambos se cargan en memoria al arrancar y se mantienen calientes.
- Datos: Las sesiones y estadísticas se guardan en IndexedDB en el navegador. Nada de bases de datos, nada de servidores. Abres la app, practicas, cierras y tus datos se quedan ahí.
La parte más entretenida de montar fue el pipeline de procesamiento de audio. Cuando grabas, el frontend aplica un highpass filter a 80 Hz (para quitar el ruido de los soplidos y la respiración) y un compressor para normalizar el volumen. Luego el backend recibe el audio, lo procesa con Whisper para obtener los timestamps, y finalmente corta cada palabra y la compara contra el chunk equivalente del audio nativo.
Lo que me llevo
El proyecto empezó como un «a ver qué sale» y terminó siendo una herramienta que realmente uso. No es perfecta ni pretende serlo, pero cumple su función: decirte dónde metes la pata sin edulcorarlo.
Si algo he aprendido es que a veces merece la pena construir algo solo porque te apetece entender cómo funciona. Y de paso, te llevas una app que te ayuda a mejorar algo que te importa.
El código está en GitHub con licencia MIT. Corre con Docker y funciona con o sin GPU.