La idea empezó de una forma bastante tonta. Estaba estudiando inglés —otra vez— y me di cuenta de algo que llevaba años haciendo mal: trataba cada palabra como si flotara sola en el espacio. Como si el idioma fuera una sopa de letras.
Spoiler: no funciona así. El inglés es un sistema de estructuras que se repiten: «I don’t know if», «going to be», «a lot of». Cosas que dices sin pensar porque las has oído mil veces. Y ahí me asaltó la pregunta: ¿cuántas de estas estructuras necesitas saber para cubrir la mayoría de lo que aparece en una conversación real?
No era una pregunta retórica. Me obsesionó.
El experimento (o «cómo convertir 7 series de TV en un problema de optimización»)
Construí un corpus con 697.547 frases (~4,04 millones de tokens) de siete series: Doctor Who, The Office, FRIENDS, The Big Bang Theory, How I Met Your Mother, Skins y Scrubs. La selección no es aleatoria: cubren desde el británico más británico hasta el californiano más californiano, pasando por adolescentes con problemas existenciales.
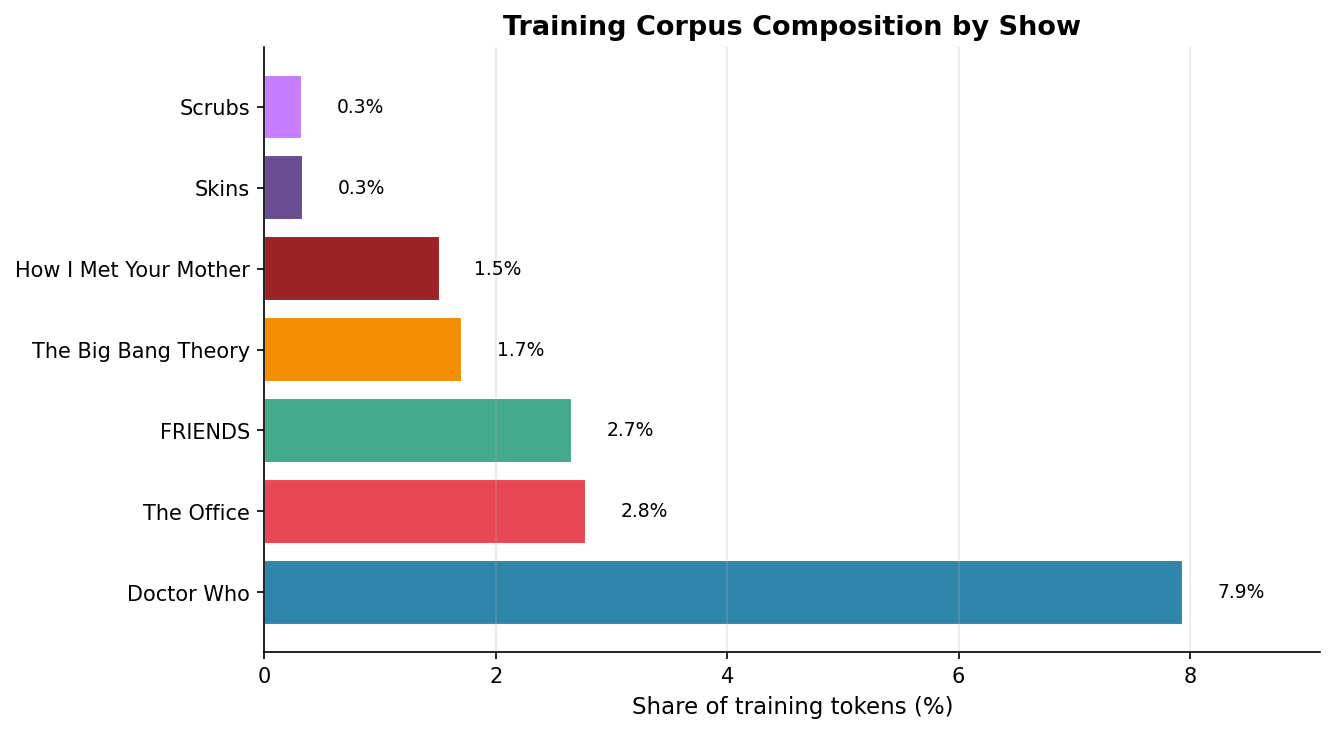
Sí, Doctor Who domina el 79% del corpus. Mitigué el sesgo con un cap de 8 ejemplos por serie durante la indexación e interleaving por shows. No os preocupéis, los Daleks no contaminan los datos.
Extracción de candidatos
De ese corpus extraje todos los n-gramas de longitud 2–5 con frecuencia ≥ 5 en al menos 2 series distintas. Para cada span genero dos tipos de chunk:
- Lexical: los tokens exactos («I don’t know»)
- Slotted: con comodines POS («to {verb} the»), mínimo 2 tokens literales, máximo 2 slots.
Resultado: ~100.000 candidatos. Demasiados para estudiarlos todos (a no ser que tengas 3 vidas).
Selección greedy (o «el algoritmo que decide qué merece la pena»)
Modelé el problema como un set cover ponderado: dado un corpus de tokens, quiero elegir los chunks que cubran el máximo número de posiciones con el mínimo número de tarjetas. Es el mismo tipo de problema que resuelven las compañías de telecomunicaciones para colocar antenas, solo que aquí las «antenas» son frases de FRIENDS.
Aplico CELF (Cost-Effective Lazy Forward), que garantiza una solución a (1 − 1/e) ≈ 63% del óptimo con coste O(n log n). Traducción: es 100× más rápido que la fuerza bruta y apenas pierdes calidad.
Los resultados (prepárate, que vienen curvas)
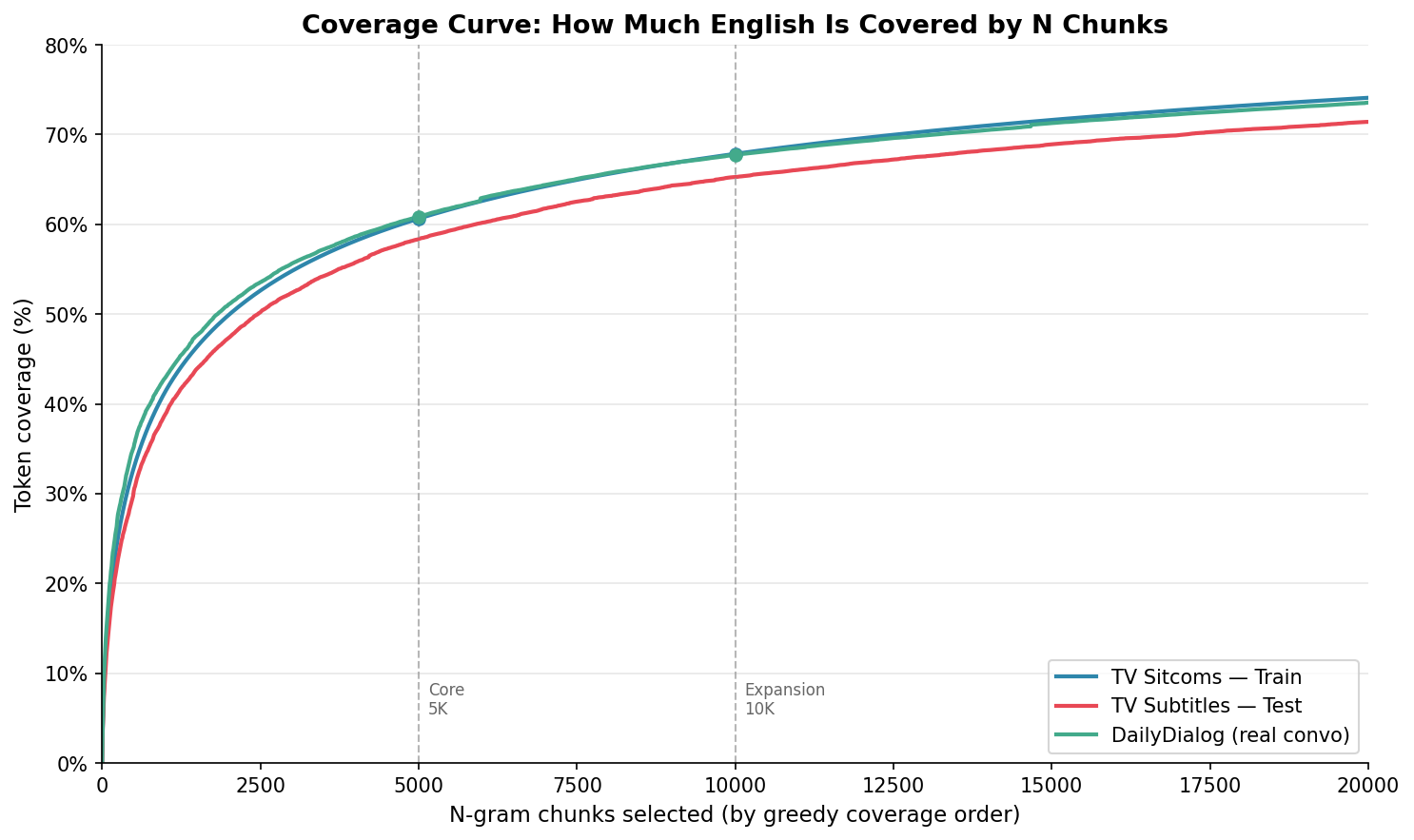
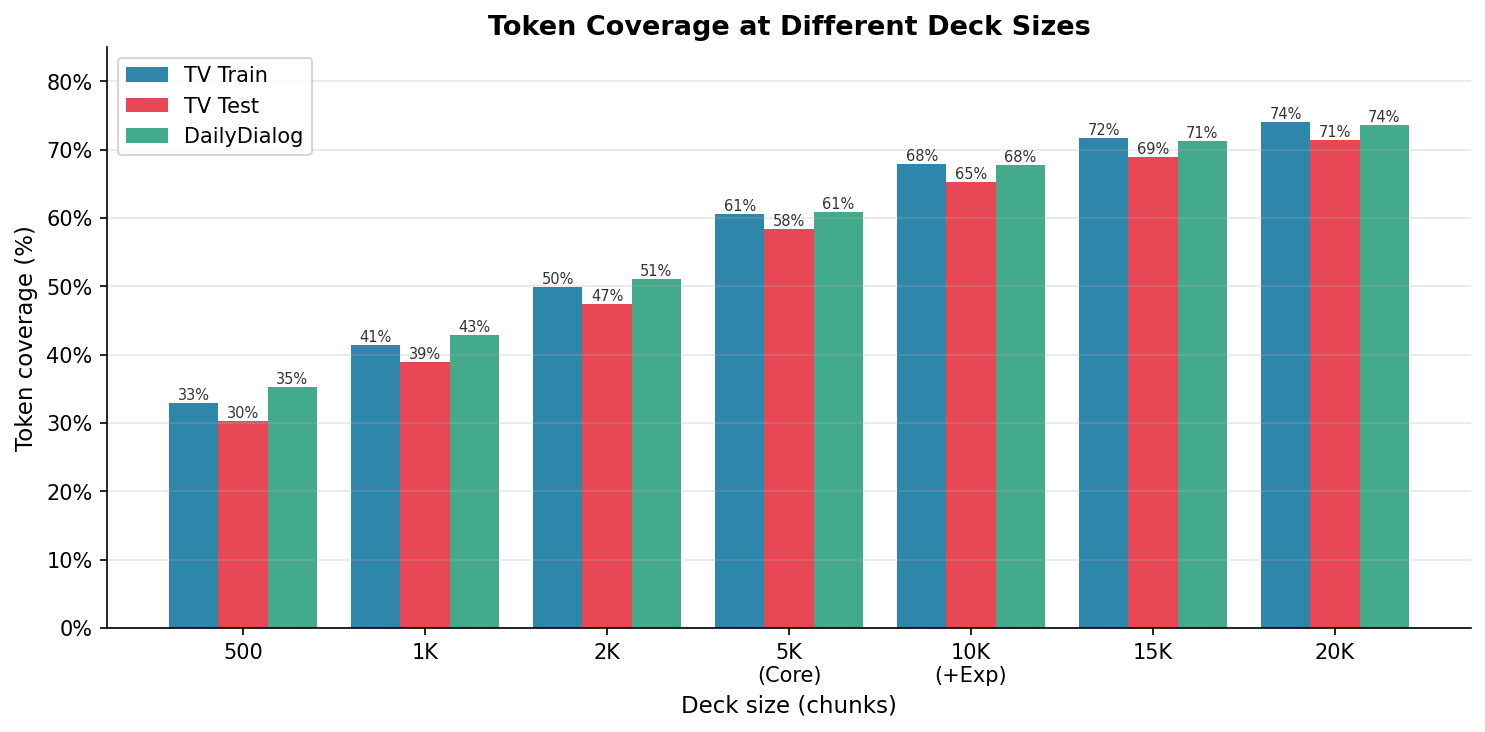
Mira esas tres curvas. Son casi perfectamente paralelas: TV Train, TV Test y DailyDialog (otro corpus conversacional). Eso sugiere que las estructuras que aprendes de las series generalizan bien a otros corpus conversacionales escritos. Más abajo vuelvo sobre esto y sus límites.
| N chunks | TV Train | TV Test | DailyDialog |
|---|---|---|---|
| 100 | 16,5% | — | — |
| 500 | 32,9% | 30,3% | 35,2% |
| 1.000 | 41,4% | 38,9% | 42,9% |
| 5.000 | 60,6% | 58,4% | 60,9% |
| 10.000 | 67,9% | 65,3% | 67,7% |
| 20.000 | 74,1% | 71,4% | 73,6% |
Con 5.000 estructuras cubres el 60,9% de los tokens del corpus conversacional. Con 10.000, el 73,6%. Y luego la cosa se estanca.
Una aclaración importante: cobertura de tokens no es lo mismo que comprensión de una conversación. Si un chunk como «I don’t know» cubre 3 tokens, eso no significa que entiendas el contexto, la intención o el registro en que se usa. Significa que, estadísticamente, esos 3 tokens aparecen en el texto y tu mazo los incluye. La comprensión real depende de factores (sintaxis, semántica, pragmática, referencias culturales) que este análisis no mide.
La ley de Zipf aplicada a estructuras (o «los retornos marginales son una putada»)
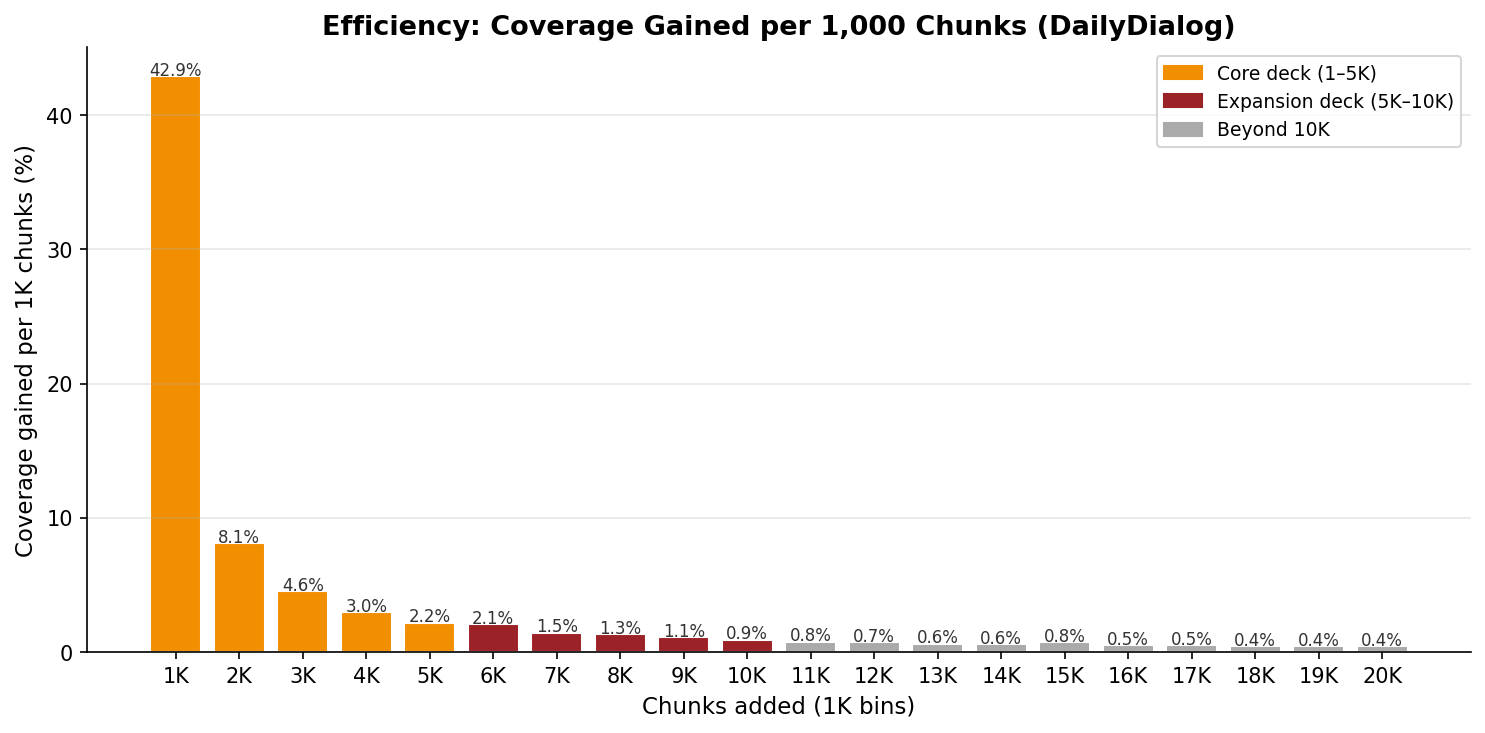
Esta gráfica duele (en el buen sentido):
- Primer bloque (1–1K): +42,9 puntos porcentuales de cobertura. Casi te dan ganas de llorar de lo eficiente que es.
- Segundo bloque (1K–2K): +8,1 pp. Todavía bien.
- Tercer bloque (2K–3K): +4,6 pp. Empieza a doler.
- Bloques 5K–10K: 1–2 pp cada uno. Ya estamos en modo suffering.
- Bloques 10K–20K: < 1 pp cada uno. Esto ya es por orgullo.
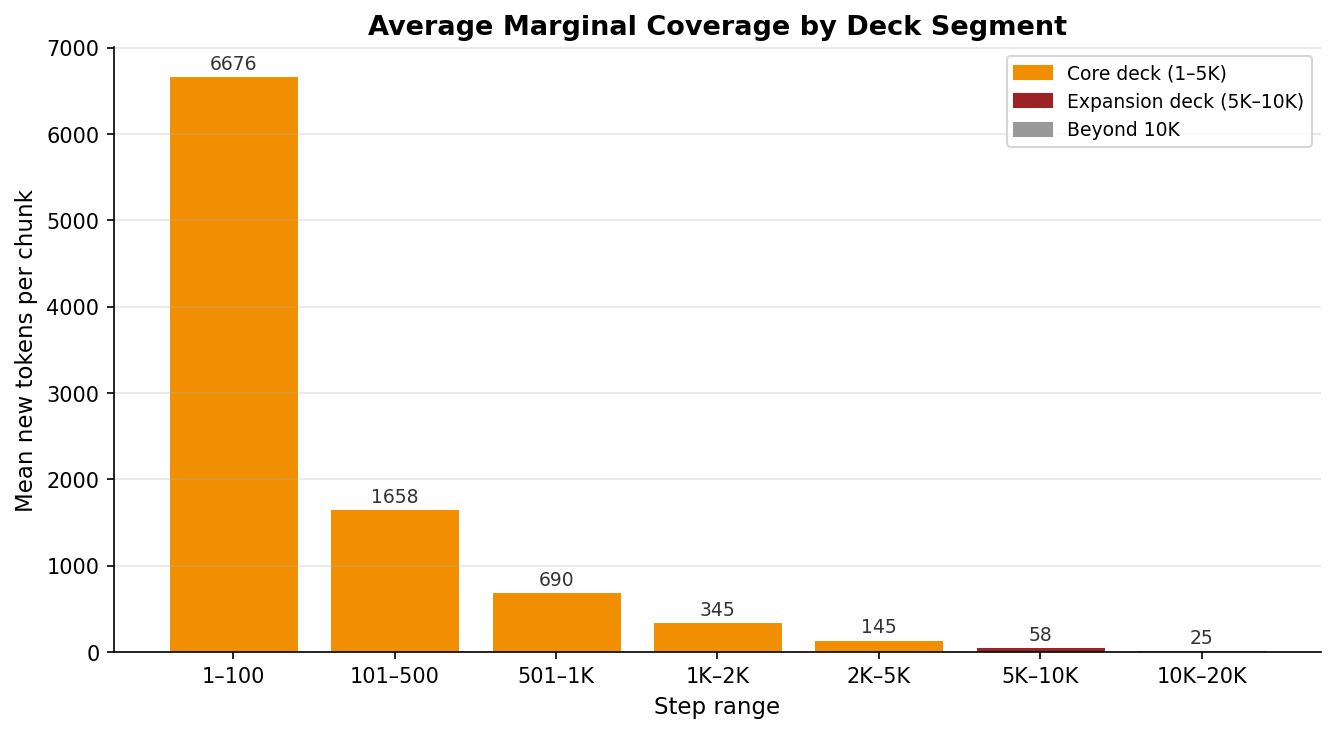
En términos de tokens nuevos por chunk, la caída es aún más dramática:
| Rango | Media tokens/chunk | Respecto al inicio |
|---|---|---|
| 1–100 | 6.676 | 100% |
| 101–500 | 1.658 | 25% |
| 501–1.000 | 690 | 10% |
| 1.000–2.000 | 345 | 5% |
| 2.000–5.000 | 145 | 2% |
| 5.000–10.000 | 58 | 0,9% |
| 10.000–20.000 | 25 | 0,4% |

Los primeros 100 chunks te dan 6.676 tokens nuevos cada uno. Los últimos 10.000 te dan 25. Veinticinco. Es como pasar de regar con manguera a regar con cuentagotas.
La gran pregunta: ¿esto es «inglés de TV» o inglés de verdad?
Esta era mi mayor miedo. Si las estructuras solo funcionan para hablar como Sheldon Cooper, el proyecto no sirve para nada.
Usé DailyDialog (Li et al., 2017) como corpus de validación externa: 102.979 diálogos escritos por investigadores que no forman parte del entrenamiento. Si las curvas divergían, sabría que había overfitting al registro televisivo.
Resultado:
| Corpus | Cobertura con 20K chunks |
|---|---|
| TV Train (in-domain) | 74,1% |
| DailyDialog | 73,6% |
| Diferencia | +0,54 pp |
0,54 puntos porcentuales. Es una buena señal: las estructuras extraídas de series generalizan bien a otro corpus conversacional.
Ahora bien, ojo con lo que esto no demuestra. DailyDialog es un corpus escrito y limpio, sin interrupciones, sin errores, sin acentos, sin ruido de fondo. Las conversaciones reales tienen todo eso, y la comprensión en vivo depende de factores que este análisis no captura: velocidad de habla, solapamiento de turnos, referencias culturales, ironía, contexto situacional.
Lo razonable es decir: las estructuras generalizan bien a texto conversacional escrito. La validación con conversación oral real (con acentos, ruido e interrupciones) queda pendiente.
¿Y por qué narices no se llega al 100%?
Buena pregunta. Con este método concreto, la cobertura se estanca en ~74%. No es por falta de datos, sino por tres razones:
Una advertencia antes: este límite no es una propiedad fundamental del inglés. Depende de decisiones metodológicas: n-gramas de longitud 2–5, exclusión de unigramas, chunks léxicos y slotted, corpus de TV, algoritmo CELF. Si cambiáramos esas variables —permitiendo estructuras más largas, dependencias sintácticas o modelos semánticos— el porcentaje probablemente cambiaría. Dicho esto, las razones concretas de este techo son:
1. El problema del unigrama solitario. Los tokens no cubiertos más frecuentes son…
| Token | Veces que aparece sin cubrir |
|---|---|
| and | 4.297 |
| ‘s (contracción) | 3.797 |
| ‘t (contracción) | 3.674 |
| i | 2.822 |
| yes | 2.386 |
| please | 2.121 |
…palabras ultrafrecuentes que aparecen solas («Yes.», «OK.», «Please.»). Mi sistema solo selecciona chunks de 2+ tokens, así que estos se cuelan. Podría añadir unigramas, pero entonces el mazo incluiría tarjetas como «the». No gracias.
2. Combinatoria fraseológica infernal. El inglés conversacional tiene una combinatoria casi infinita. Las mismas palabras se combinan de formas ligeramente distintas en cada conversación. Ningún conjunto finito de n-gramas de longitud 2–5 puede capturarlas todas.
3. Vocabulario de cola larga. El 25% restante son términos técnicos, nombres propios, neologismos — cosas que aparecen una vez cada mil conversaciones. No están en los top-20K de un corpus de TV, ni deberían estarlo.
Conclusión: el 74% no es un fallo del método. Es un techo de este método concreto, no una propiedad fundamental del inglés en sí.
La decisión de diseño: dos mazos, no uno
La curva de eficiencia tiene un quiebre claro en 5.000 chunks. Por eso dividí el resultado en dos mazos:
| Core (1–5K) | Expansion (5K–10K) | |
|---|---|---|
| Cobertura DailyDialog | 60,9% | +12,7 pp → 73,6% |
| Ratio esfuerzo/impacto | Muy alto | Moderado |
| Perfil de aprendiz | Principiante–intermedio | Intermedio–avanzado |
| Recomendación | Obligatorio | Opcional (B2+) |
Core: 5.000 estructuras, 60,9% de cobertura de tokens. Esto cubre más de la mitad de las palabras de cualquier corpus conversacional. Es el mazo que todo el mundo debería estudiar.
Expansion: otras 5.000, 73,6% acumulado. El porcentaje sube, pero el esfuerzo por tarjeta es mucho mayor. Recomendado si ya tienes un B2 y quieres pulir.
La composición de los mazos

| Core (1–5K) | Expansion (5K–10K) | |
|---|---|---|
| Bigramas (n=2) | 84,9% | 84,0% |
| Trigramas (n=3) | 11,9% | 11,4% |
| Cuatrigramas (n=4) | 3,2% | 4,5% |
| Pentagramas (n=5) | < 0,1% | < 0,1% |
| Lexical | 85,6% | 84,6% |
| Slotted | 14,4% | 15,4% |
Mayoritariamente bigramas léxicos. Los slotted (con comodines) aumentan ligeramente en expansión — son estructuras más específicas que merecen la pena solo cuando ya tienes la base.
Los 10 chunks más valiosos
| # | Patrón | Tipo | Frec. | Series | Tokens nuevos | Cobertura acum. |
|---|---|---|---|---|---|---|
| 1 | in the | lexical | 9.587 | 7 | 19.174 | 0,5% |
| 2 | i don’t | lexical | 9.133 | 7 | 18.266 | 0,9% |
| 3 | you know | lexical | 8.783 | 7 | 17.566 | 1,4% |
| 4 | of the | lexical | 8.749 | 7 | 17.498 | 1,8% |
| 5 | do you | lexical | 8.216 | 7 | 15.543 | 2,6% |
| 6 | are you | lexical | 8.163 | 7 | 16.323 | 2,2% |
| 7 | this is | lexical | 7.033 | 7 | 14.066 | 2,9% |
| 8 | to the | lexical | 6.767 | 7 | 13.534 | 3,3% |
| 9 | going to | lexical | 6.397 | 7 | 12.647 | 3,6% |
| 10 | to {verb} the | slotted | 3.897 | 7 | 11.444 | 3,9% |
Fíjate: todos aparecen en las 7 series. No hay jerga de una serie concreta. Son estructuras universalmente conversacionales. Y el primero con comodín (el #10, «to {verb} the») demuestra que los patrones abstractos también importan — pero mucho menos que los chunks léxicos puros.
Cómo están diseñadas las tarjetas
Odio las tarjetas que te muestran el patrón abstracto («I don’t ___») y esperan que adivines. Eso no es aprender un idioma, es hacer un crucigrama.
Mis tarjetas son sentence-first (cloze):
Frente:
_____ make of it, but she looked really happy.Reverso:
I don’t know what to make of it, but she looked really happy.
No sé qué pensar, pero ella parecía muy feliz.
— FRIENDS · #847
El diseño fuerza la recuperación en contexto — exactamente la habilidad que necesitas cuando alguien te suelta una estructura en medio de una conversación y tienes que procesarla en tiempo real.
Cada tarjeta incluye hasta 3 frases de ejemplo de series distintas, con un máximo de 8 ejemplos por serie para evitar el sesgo de Doctor Who. Traducción al español y audio TTS incluidos.
Para quién es esto
Si estás aprendiendo inglés y quieres optimizar tu tiempo de estudio (asumiendo que no te sobra el tiempo, que a nadie le sobra), estos mazos son para ti.
En lugar de memorizar listas de vocabulario que nunca aparecen juntas en la vida real, aprenderás las estructuras que más aparecen en los corpus conversacionales, ordenadas por su impacto real en cobertura de tokens. La primera tarjeta del mazo («in the») te da más cobertura que las últimas 5.000 juntas.
Eso no es marketing. Es un hecho estadístico.
Limitaciones del análisis (para que no te lleves a engaño)
Este estudio tiene varias limitaciones que merece la pena dejar claras:
- Las series no son conversación real. El corpus principal son diálogos escritos por guionistas. Aunque la validación con DailyDialog muestra resultados consistentes, ambos corpus son texto limpio sin los problemas del habla real (acentos, ruido, tartamudeos, interrupciones).
- Cobertura de tokens ≠ comprensión. El 74% mide qué proporción de palabras aparecen en los chunks seleccionados, no cuánto entiendes de una conversación. La comprensión real requiere sintaxis, semántica, pragmática y conocimiento del mundo que este método no captura.
- Techo metodológico, no lingüístico. El límite del 74% depende de nuestras decisiones concretas (n-gramas 2–5, sin unigramas, chunks léxicos+slotted). No es una constante universal del inglés.
- Sin intervalos de confianza. Los resultados son puntuales. Un análisis con validación cruzada y bootstrapping daría una imagen más robusta de la variabilidad.
- Generalización a otros dominios. El corpus son series de TV. Las estructuras óptimas para inglés médico, jurídico o académico serían distintas.
Dicho esto, el hallazgo central —los rendimientos decrecientes son brutales y conviene priorizar las primeras miles de estructuras— es lo suficientemente robusto como para guiar el estudio, incluso si las cifras exactas cambian con metodologías distintas.
El análisis molaba. Las tarjetas, no.
Hasta aquí todo bien. Los datos eran sólidos, las gráficas molaban, el algoritmo CELF era elegante. Pero cuando me senté a estudiar con las tarjetas generadas, la experiencia fue… regulera.
El problema no eran los números. El problema era que cobertura estadística ≠ utilidad pedagógica. Y ese detalle se me coló por completo.
Las tarjetas tenían cinco problemas gordos:
- Contexto de sitcom. Aprender inglés con frases de FRIENDS está bien si tu objetivo vital es entender a Chandler Bing. Para leer un paper, escribir un email formal o mantener una conversación que no suene a guion de televisión, necesitas fuentes diversas.
- Sin progresión de dificultad. La tarjeta #1 era «in the». La #847 era «I don’t know what to make of it». No hay A1→C1, no hay gramática. Es como aprender a nadar empezando por el trampolín de 10 metros. La frecuencia bruta no es un plan de estudios.
- Sin traducciones ni explicaciones. Saber que «going to» aparece 6.397 veces no te dice qué significa ni cuándo usarlo. Las tarjetas eran sentence-first, pero sin traducción al español ni nota gramatical. Si ya sabías la estructura, bien. Si no, estabas jugando al ahorcado.
- Sin audio. Aprender chunks sin escucharlos es como aprender a cantar leyendo partituras. El bucle fonológico es esencial para la retención, y yo lo ignoré olímpicamente.
- Demasiadas tarjetas para tan poca cosa. Las últimas 5.000 estructuras de Expansion aportaban menos del 1% de cobertura cada una. Estudiar 5.000 tarjetas para subir 6 puntos porcentuales es una inversión de tiempo cuestionable, como poco.
El sistema era un ejercicio académico interesante —de hecho, creo que el análisis de cobertura y el algoritmo CELF son lo mejor del proyecto— pero como herramienta de estudio era un fracaso. Así que hice lo que cualquier persona razonable haría: tirarlo a la basura y empezar de cero.
FluentForge: lo que construí en su lugar
La pregunta correcta no era «¿qué estructuras aparecen más en las series?» sino «¿qué necesita saber un hispanohablante para entender inglés de verdad?».
Y para eso no necesitas 10.000 chunks de FRIENDS. Necesitas:
- Vocabulario de frecuencia real — no de series de TV, sino de corpus lingüísticos diseñados para esto: NGSL (New General Service List), NAWL (New Academic Word List), y NGSL-S (spoken).
- Gramática progresiva — de A1 a C1, cubriendo los errores típicos de hispanohablantes (que no son los mismos que los de un alemán o un japonés).
- Audio nativo — cada palabra y cada oración, generado por TTS con Edge-TTS (voz Sonia Neural británica).
- Traducción al español y notas gramaticales — porque estudiar sin tu L1 es absurdo.
FluentForge es un pipeline automatizado que genera mazos Anki completos a partir de fuentes académicas reales. Nada de series. Nada de CELF. Pura lingüística de corpus aplicada a la enseñanza.
Lo que hay dentro
| # | Mazo | Tarjetas | Audio | Tipo |
|---|---|---|---|---|
| 1 | Core Vocabulary | 5.666 | 5.666 | Vocabulario EN→ES + ES→EN (NGSL) |
| 2 | Grammar & Usage | 1.410 | 1.068 | Gramática Cloze + Phrasal Verbs + Collocations |
| 3 | Real English | 530 | 298 | Bundles léxicos + Idioms + False Friends |
| 4 | Academic Edge | 958 | 1.916 | Vocabulario académico (NAWL) |
| TOTAL | 8.564 | 8.948 | ||
Cada tarjeta incluye: traducción al español, transcripción fonética (IPA), badges de categoría gramatical y nivel CEFR, oración de ejemplo contextualizada, nota de género para cognados, y audio nativo en ambas caras. Las plantillas tienen CSS propio con modo nocturno — que uno estudia a las 2 AM y los ojos se resienten.
Vista previa
Así se ven las tarjetas en Anki (modo claro; también tienen modo nocturno):
Índice de mazos — los 4 mazos organizados en subdecks:
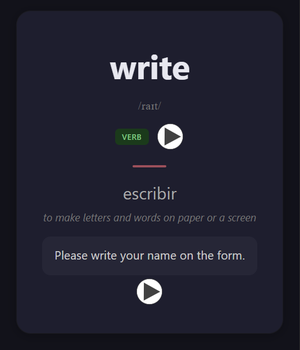
Core Vocabulary — frente (EN→ES) y reverso con traducción, IPA, ejemplo y audio:

Grammar & Usage — frente (cloze) y reverso con explicación gramatical en español:
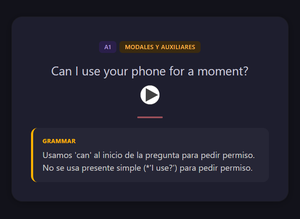
Real English: False Friends — frente (palabra española + traducción incorrecta) y reverso con la corrección:


Cómo está construido
El pipeline tiene 5 fases:
- Fase 0 — Índices: parsea dos guías markdown (gramática inglesa A1-C1 y taxonomía de bundles léxicos) y genera índices JSON con 356 puntos gramaticales atómicos y ~298 expresiones multi-palabra.
- Fase 1 — Normalización: limpia los CSVs de NGSL, NGSL-S y NAWL. Esto tiene su miga: NGSL-S viene en Latin-1 con espacios non-breaking (\xa0), NAWL en UTF-8-BOM con una entrada corrupta (DESCENDENT, definición vacía), y NGSL tiene un typo en la cabecera («Definitons» en vez de «Definitions»). Todo eso se normaliza a JSON canónico.
- Fase 2 — Enriquecimiento LLM: usa DeepSeek V4 Flash para generar traducciones, POS tags, oraciones de ejemplo A2-B1 (para NGSL) y C1 con mitigación de pistas (para NAWL). Para gramática, genera 3 variantes de oraciones cloze por punto gramatical usando vocabulario NGSL. Con reintentos automáticos si el modelo falla.
- Fase 3 — Audio TTS: Piper TTS genera audio para cada palabra y oración (~9.000 archivos). WAV → MP3 192kbps via ffmpeg. Velocidad ajustada por tipo: 0.85x para palabras aisladas, 1.0x para oraciones, 0.95x para sintaxis.
- Fase 4 — Build: ensambla los .apkg con genanki, aplicando interleaving por categoría para evitar interferencia semántica. Las cartas de gramática se ordenan por CEFR (A1 primero, C1 al final) para que las primeras sesiones solo veas presente simple en lugar de inversiones condicionales.
Estudio de cobertura: ¿cuánto inglés cubre esto de verdad?
La pregunta que obsesionaba al LanguageDomain sigue siendo válida. Pero en lugar de medir cobertura de chunks de TV sobre un corpus de TV, medí cobertura de vocabulario real sobre un corpus de verdad.
El corpus: 6,3 millones de tokens del NLTK (Brown, Reuters, Gutenberg, Webtext, discursos inaugurales y State of the Union), dividido en 5 registros. Tokenización y lematización con NLTK (WordNet + POS tagging).
Resultados por registro
| Registro | Tamaño | Cobertura total | NGSL solo | NAWL añade |
|---|---|---|---|---|
| Discursos políticos | 0.5M tokens | 86.27% | 84.56% | +1.35% |
| Académico | 0.5M | 83.66% | 80.98% | +2.27% |
| Ficción (Gutenberg) | 3.0M | 77.24% | 75.93% | +0.82% |
| Conversación (web) | 0.4M | 75.79% | 74.53% | +1.01% |
| Noticias (Reuters) | 1.9M | 74.81% | 72.59% | +1.42% |
| COMBINADO | 6.3M | 77.80% | 76.08% | +1.18% |
El dato que más mola: NGSL solo (2.809 palabras) cubre el 76.08% de los tokens. Eso son tres cuartas partes del inglés con menos de 3.000 palabras bien elegidas. NAWL añade otro 1.18% — poco en porcentaje, pero crucial en textos académicos donde llega al 2.27%.
Además, el 6.89% de las oraciones contienen al menos una expresión multi-palabra (bundle, phrasal verb, idiom o collocation) enseñada por los mazos. Las más frecuentes: according to (1.166 ocurrencias), as well as (665), kind of (572).
Limitaciones del estudio
- Corpus envejecido: Brown es de 1961, Gutenberg del siglo XIX. Con COCA o BNC los números probablemente subirían un par de puntos.
- Lematizador NLTK (~93% precisión): spaCy sería más preciso (~97%) y daría coberturas ligeramente superiores.
- Conversación = texto de foros: no es habla oral real con acentos, ruido e interrupciones.
- Cobertura de tokens ≠ comprensión: saber el 78% de las palabras no significa entender el 78% de lo que lees. Nation (2006) sitúa el umbral de comprensión sin diccionario en el 95-98%.
LanguageDomain vs FluentForge: la comparación
| LanguageDomain | FluentForge | |
|---|---|---|
| Fuente | 7 series de TV | NGSL, NAWL, guías gramaticales |
| Elementos | 10.000 chunks n-grama | 3.790 lemas + 775 expresiones + 356 puntos gramaticales |
| Progresión | Frecuencia bruta (no pedagógica) | CEFR (A1→C2) + frecuencia |
| Audio | No | Sí (~9.604 archivos MP3) |
| Traducción ES | No | Sí, en cada tarjeta |
| Notas gramaticales | No | Sí, en español, enfocadas a errores de hispanohablantes |
| IPA fonética | No | Sí |
| Modo nocturno | No | Sí |
| Cobertura | 74% (20K chunks, corpus TV) | 77.8% (3.790 lemas, corpus NLTK 6.3M) |
| Eficiencia | 0.0037 pp/tarjeta | 0.020 pp/tarjeta (5.4× mejor) |
| Veredicto | Análisis sólido, inútil para estudiar | Estudiable, reproducible, con datos |
La diferencia de eficiencia es bestial: FluentForge te da 5.4 veces más cobertura por tarjeta. Y son tarjetas que realmente puedes estudiar sin sentir que estás haciendo un crucigrama.
Cómo estudiarlo (sin volverte loco)
Los mazos están diseñados para estudiarse con Anki. Aquí va la estrategia:
Orden de estudio recomendado
| Fase | Mazo | Cartas nuevas/día | Duración aprox. |
|---|---|---|---|
| 1 | Core Vocabulary | 15–20 | 4–6 meses |
| 2 | Grammar & Usage | 10–15 | 2–3 meses |
| 3 | Real English | 5–10 | 2–3 meses |
| 4 | Academic Edge | 10–15 | 2–3 meses |
Empieza por Core Vocabulary. Cubre el 76% del inglés. Sin esto, lo demás no sirve. Las primeras 500 palabras (las más frecuentes) te dan más retorno que las últimas 2.000 juntas — la misma ley de rendimientos decrecientes que vimos en LanguageDomain, pero aplicada a vocabulario real en lugar de chunks de TV.
Grammar & Usage está ordenado por CEFR. Las primeras 105 cartas son A1 (to be, presente simple, there is/are). Las últimas 171 son C1 (inversiones, cleft sentences, subjuntivo). Con 15 cartas nuevas al día, las primeras dos semanas solo ves nivel básico. Las inversiones no aparecen hasta la séptima semana. La progresión es natural y no requiere que configures nada en Anki.
Real English y Academic Edge son para después. Los bundles léxicos cobran sentido cuando ya tienes contexto. El vocabulario académico de NAWL asume que dominas el vocabulario general. No los actives hasta que lleves al menos un mes con Foundations.
El SRS de Anki hace el resto: te muestra cada tarjeta justo antes de que la olvides. Los mazos se solapan naturalmente — no necesitas «terminar» uno para empezar el siguiente.
Descarga
El mazo completo en un solo archivo .apkg con los 4 sub-mazos y todo el audio — listo para importar en Anki 2.1.65+:
Descargar FluentForge.apkg (140 MB)
Contiene: Core Vocabulary (5.666 tarjetas), Grammar & Usage (1.460), Real English (562), Academic Edge (1.916) — 9.604 tarjetas en total con 9.604 archivos MP3 de audio TTS.
Instrucciones: descarga el archivo e impórtalo en Anki con Archivo → Importar. El audio está embebido en el propio .apkg, no necesitas instalar nada adicional.
Instrucciones: descarga los archivos .apkg e impórtalos en Anki con Archivo → Importar. Los 4 mazos incluyen audio TTS (voz Sonia Neural, Edge-TTS) en cada tarjeta — ~9.604 archivos MP3 en total. El audio está embebido en el propio .apkg, no necesitas instalar nada adicional.
Actualización v2.2 (Junio 2026)
El mazo ha crecido. Después de usarlo yo mismo durante unas semanas y recibir feedback, he metido varios cambios:
- Sub-decks por CEFR. Core Vocabulary ya no es un único mazo plano de 2.833 palabras — ahora está dividido en A1 (701), A2 (1.373), B1 (438) y B2 (321). Academic Edge también se divide en B2 y C1. Esto permite que Anki te muestre primero las palabras más frecuentes y vayas subiendo de nivel de forma natural, igual que en el mazo de gramática.
- Producción en Academic Edge. El mazo académico ahora es bidireccional: no solo reconoces la palabra (EN→ES), también la produces (ES→EN). De 958 tarjetas pasamos a 1.916. Si Foundation tiene reverse, Academic también.
- Audio en todos los mazos. Phrasal Verbs, Idioms, Collocations y False Friends ya tienen audio TTS en cada tarjeta. Antes solo lo tenían los mazos principales. Ahora los 9.604 archivos de audio cubren el mazo entero.
- +25 puntos de gramática C2. Inversiones literarias, subjuntivo con lest, aposición compleja, no sooner… than, doble genitivo, cleft avanzadas. De 14 puntos C2 a 39. Para cuando el B2 se te quede corto.
- Labels CEFR en todas las palabras. Las ~3.800 palabras de vocabulario ahora muestran su nivel (A1 a C1) con un badge. Ya no vas a ciegas — sabes si estás aprendiendo una palabra básica o avanzada.
- Más contenido. +32 idioms (165 total) y +51 collocations (230 total).
- Corrección de artículos. ~710 verbos tenían artículos de género incorrectos en la traducción inversa. Corregido.
Si ya tenías la v2.1: descarga el nuevo archivo e impórtalo. Anki detectará las tarjetas duplicadas y solo añadirá las nuevas. Tu progreso no se pierde.
Lo que empezó como un algoritmo greedy sobre frases de FRIENDS se convirtió en un pipeline completo de generación de mazos Anki. El análisis de cobertura del LanguageDomain era sólido —de hecho, es la base conceptual sobre la que se construyó FluentForge— pero las tarjetas no eran estudiables. A veces hace falta construir algo, ver que no funciona, tirarlo y volver a empezar. No es ciencia puntera —de hecho es bastante estándar: CSVs, llamadas a LLM, TTS y genanki— pero verlo funcionar es gratificante. Si algo he aprendido es que los datos sin pedagogía son estériles, y que 2.809 palabras bien elegidas te llevan más lejos que 10.000 chunks de televisión.