The idea started in a pretty dumb way. I was studying English —again— and I realized something I’d been doing wrong for years: I was treating every word like it floated alone in space. Like the language was alphabet soup.
Spoiler: it doesn’t work that way. English is a system of recurring structures: «I don’t know if», «going to be», «a lot of». Things you say without thinking because you’ve heard them a thousand times. And that’s when the question hit me: how many of these structures do you need to cover most of what appears in a real conversation?
It wasn’t a rhetorical question. I got obsessed.
The experiment (or «how to turn 7 TV shows into an optimization problem»)
I built a corpus with 697,547 sentences (~4.04 million tokens) from seven shows: Doctor Who, The Office, FRIENDS, The Big Bang Theory, How I Met Your Mother, Skins, and Scrubs. The selection isn’t random: it covers everything from the most British British to the most Californian Californian, plus teenagers with existential problems.
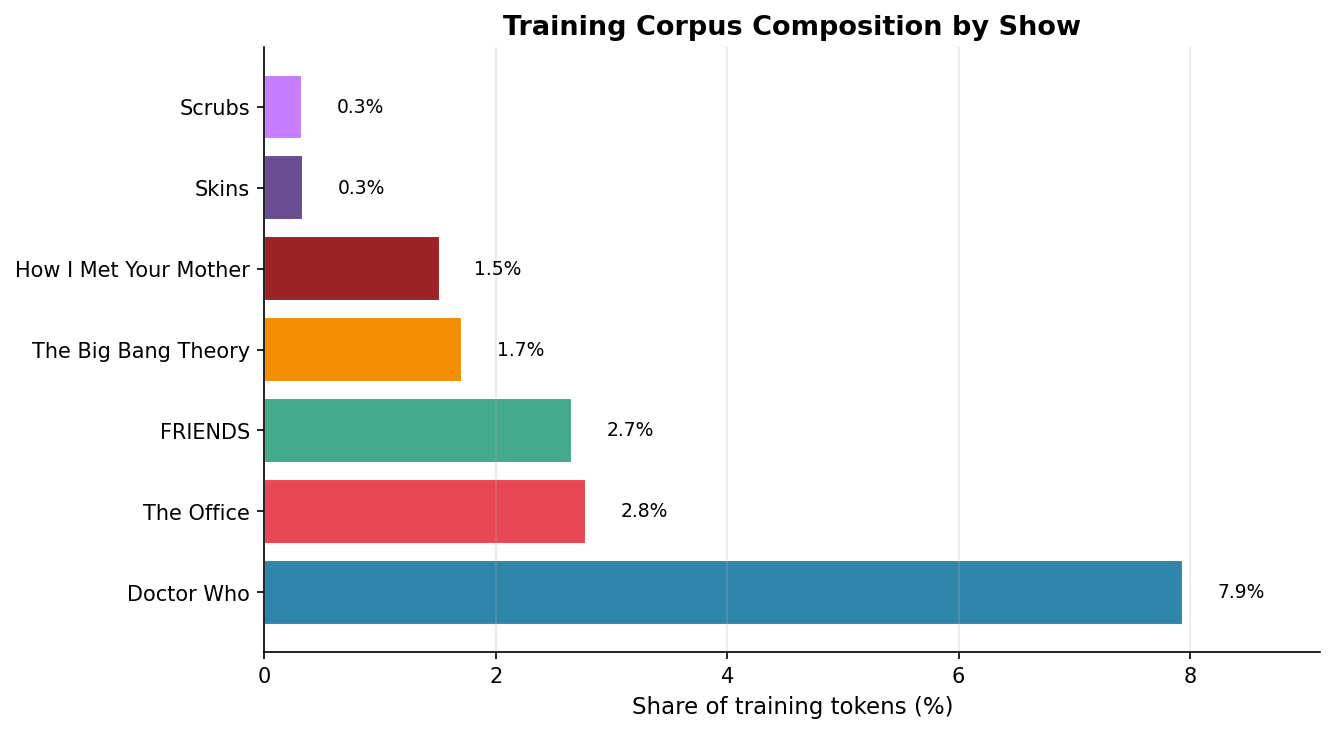
Yes, Doctor Who dominates 79% of the corpus. I mitigated the bias with an 8-example-per-show cap during indexing and interleaving by show. Don’t worry, the Daleks aren’t contaminating the data.
Candidate extraction
From that corpus I extracted all n-grams of length 2–5 with frequency ≥ 5 in at least 2 different shows. For each span I generate two types of chunk:
- Lexical: the exact tokens («I don’t know»)
- Slotted: with POS wildcards («to {verb} the»), minimum 2 literal tokens, maximum 2 slots.
Result: ~100,000 candidates. Way too many to study them all (unless you have 3 lives).
Greedy selection (or «the algorithm that decides what’s worth your time»)
I modeled the problem as a weighted set cover: given a corpus of tokens, I want to choose the chunks that cover the maximum number of positions with the minimum number of cards. It’s the same type of problem telecom companies solve to place antennas, except here the «antennas» are FRIENDS quotes.
I apply CELF (Cost-Effective Lazy Forward), which guarantees a solution within (1 − 1/e) ≈ 63% of optimal with O(n log n) cost. Translation: it’s 100× faster than brute force and you barely lose any quality.
The results (brace yourself, there are curves)
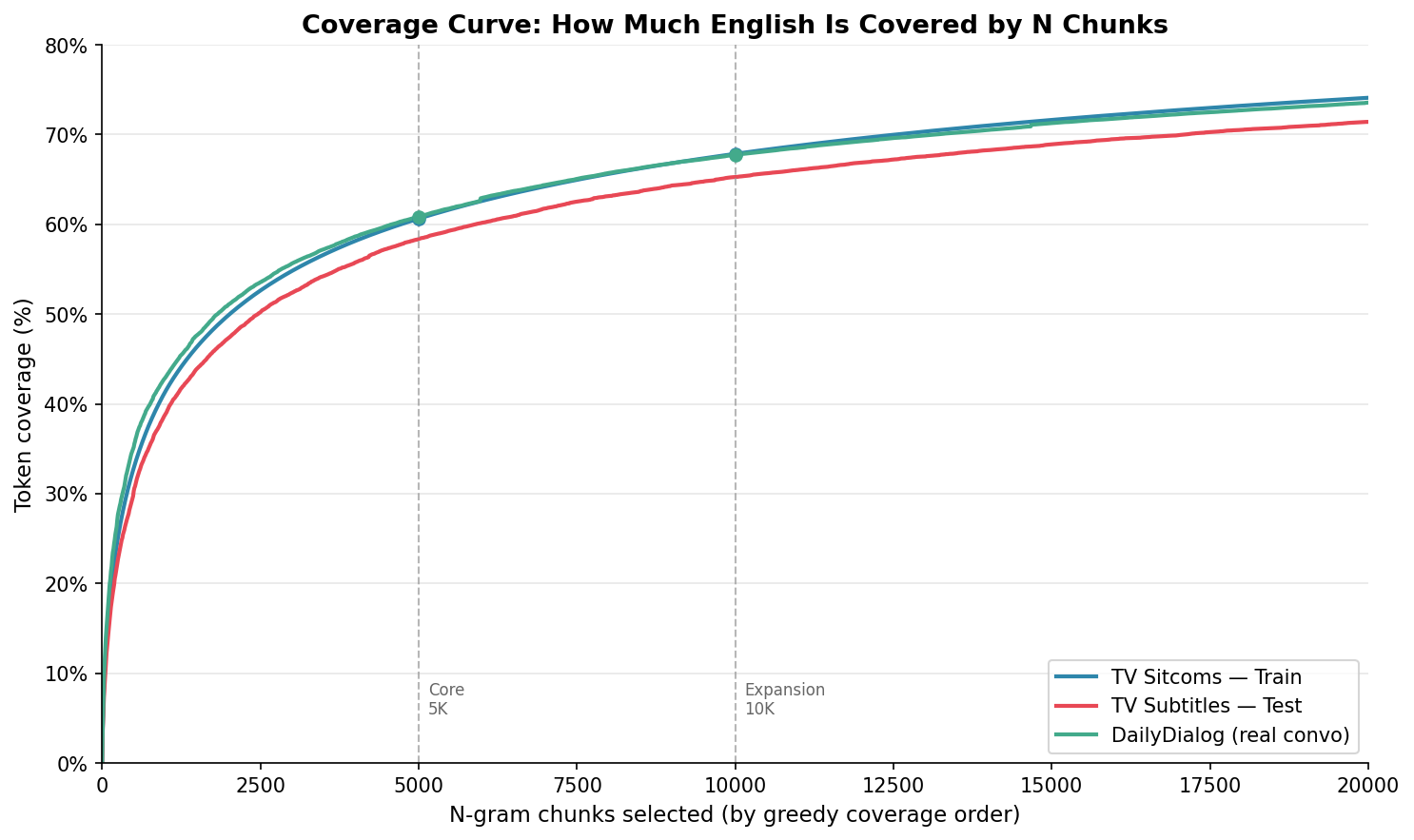
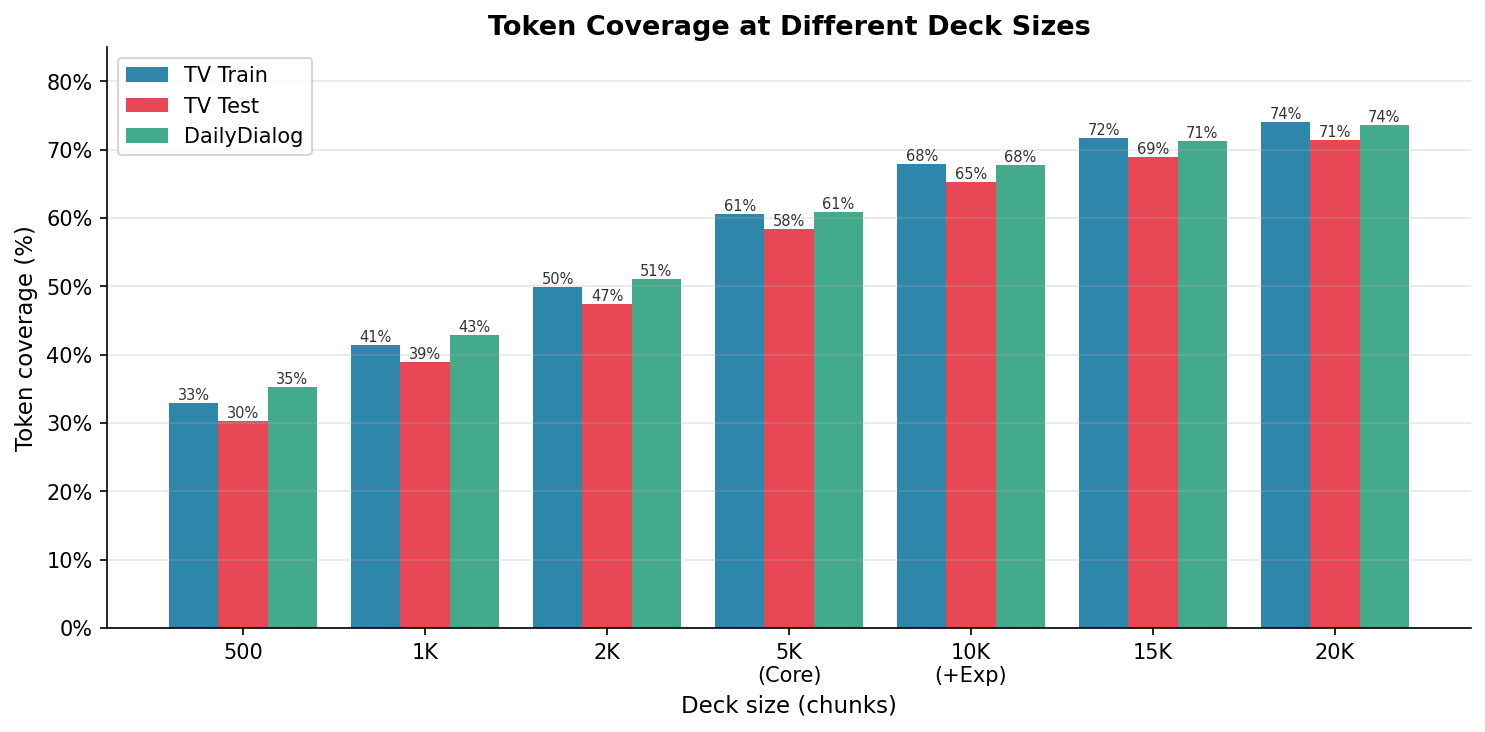
Look at those three curves. They’re almost perfectly parallel: TV Train, TV Test, and DailyDialog (another conversational corpus). This suggests the structures you learn from TV shows generalize well to other written conversational corpora. More on this and its limits below.
| N chunks | TV Train | TV Test | DailyDialog |
|---|---|---|---|
| 100 | 16.5% | — | — |
| 500 | 32.9% | 30.3% | 35.2% |
| 1,000 | 41.4% | 38.9% | 42.9% |
| 5,000 | 60.6% | 58.4% | 60.9% |
| 10,000 | 67.9% | 65.3% | 67.7% |
| 20,000 | 74.1% | 71.4% | 73.6% |
With 5,000 structures you cover 60.9% of conversational corpus tokens. With 10,000, 73.6%. And then things flatline.
An important clarification: token coverage is not the same as conversation comprehension. If a chunk like «I don’t know» covers 3 tokens, that doesn’t mean you understand the context, intent, or register in which it’s used. It means that, statistically, those 3 tokens appear in the text and your deck includes them. Real comprehension depends on factors (syntax, semantics, pragmatics, cultural references) that this analysis doesn’t measure.
Zipf’s law applied to structures (or «marginal returns are a bitch»)
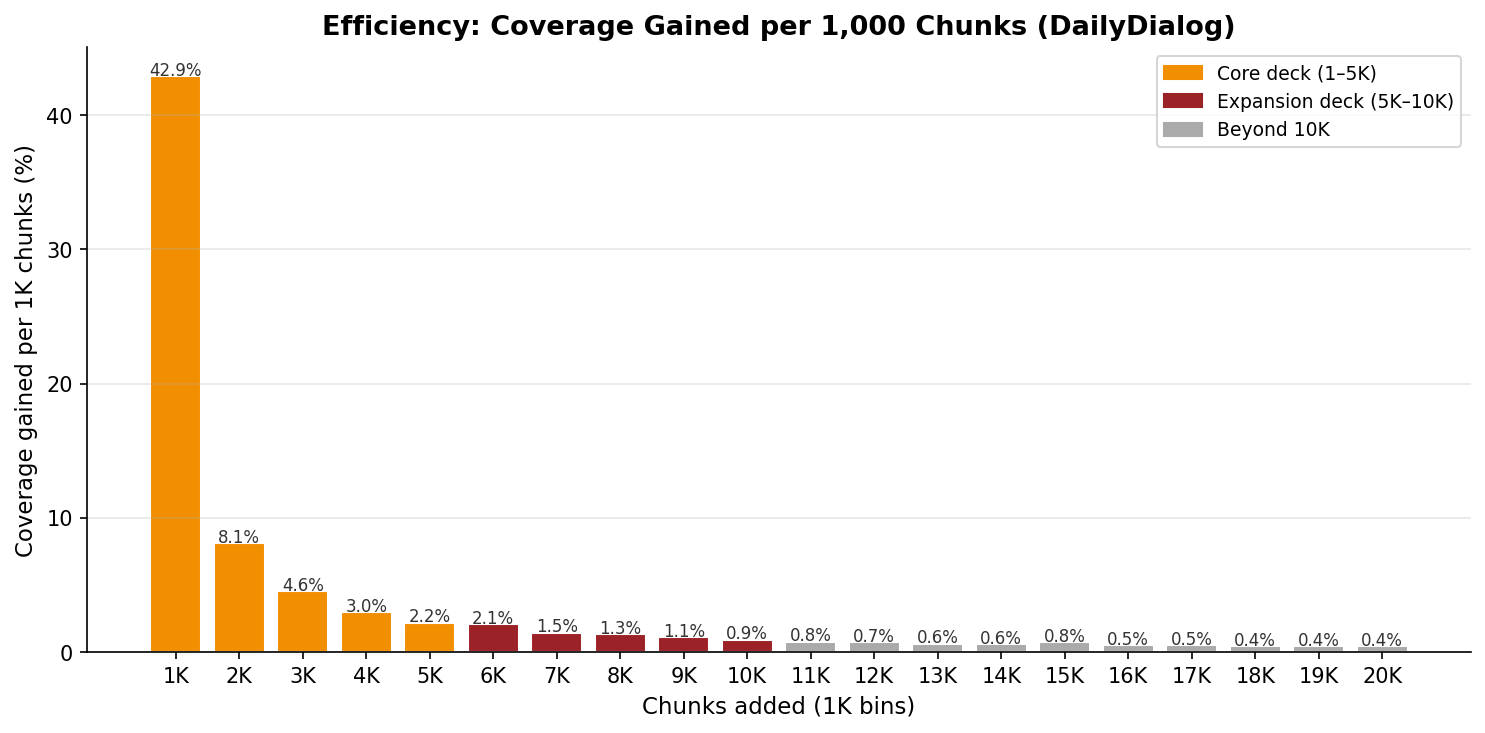
This chart hurts (in a good way):
- First block (1–1K): +42.9 percentage points of coverage. Almost makes you want to cry at how efficient it is.
- Second block (1K–2K): +8.1 pp. Still fine.
- Third block (2K–3K): +4.6 pp. Starting to hurt.
- Blocks 5K–10K: 1–2 pp each. We’re in suffering mode now.
- Blocks 10K–20K: < 1 pp each. This is just pride at this point.
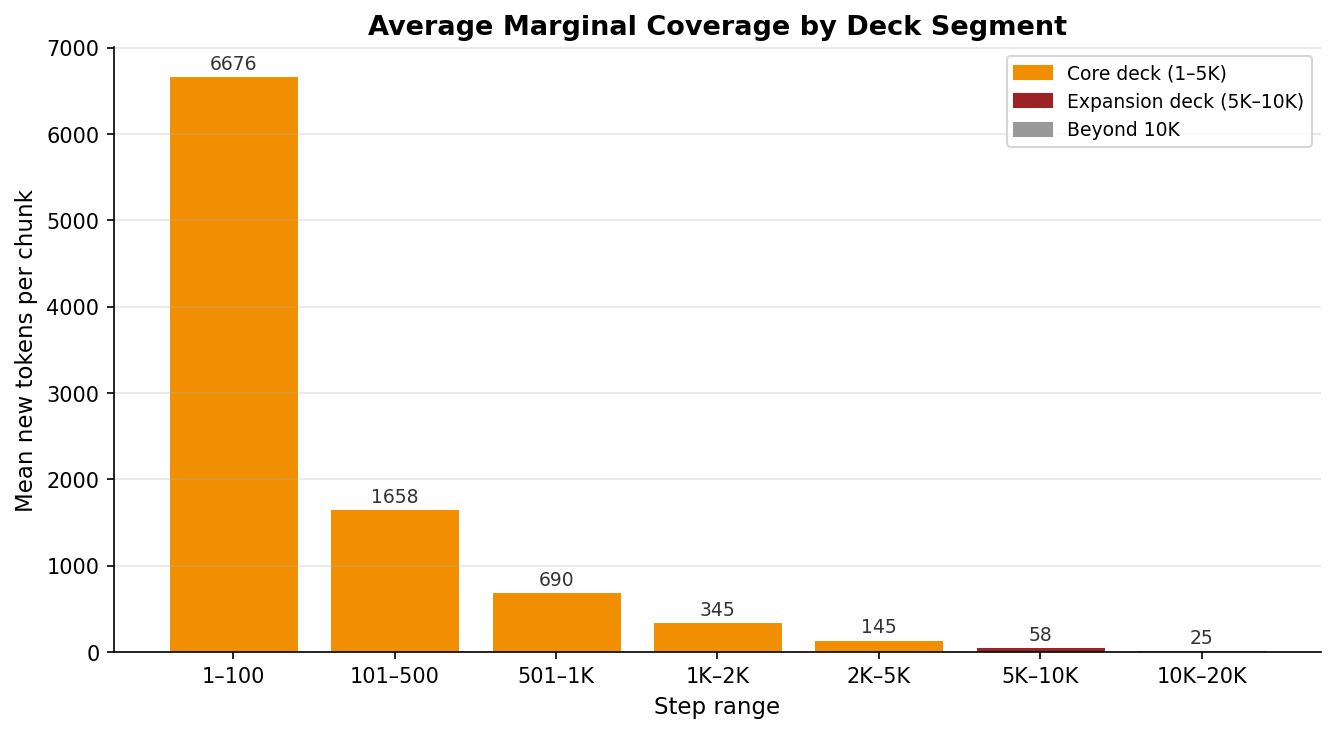
In terms of new tokens per chunk, the drop is even more dramatic:
| Range | Avg tokens/chunk | vs. start |
|---|---|---|
| 1–100 | 6,676 | 100% |
| 101–500 | 1,658 | 25% |
| 501–1,000 | 690 | 10% |
| 1,000–2,000 | 345 | 5% |
| 2,000–5,000 | 145 | 2% |
| 5,000–10,000 | 58 | 0.9% |
| 10,000–20,000 | 25 | 0.4% |

The first 100 chunks give you 6,676 new tokens each. The last 10,000 give you 25. Twenty-five. It’s like going from watering with a hose to watering with an eyedropper.
The big question: is this «TV English» or real English?
This was my biggest fear. If the structures only work for talking like Sheldon Cooper, the project is useless.
I used DailyDialog (Li et al., 2017) as an external validation corpus: 102,979 dialogues written by researchers that are not part of the training set. If the curves diverged, I’d know there was overfitting to the TV register.
Result:
| Corpus | Coverage with 20K chunks |
|---|---|
| TV Train (in-domain) | 74.1% |
| DailyDialog | 73.6% |
| Difference | +0.54 pp |
0.54 percentage points. That’s a good sign: the structures extracted from TV shows generalize well to another conversational corpus.
Now, careful with what this doesn’t prove. DailyDialog is a clean, written corpus — no interruptions, no errors, no accents, no background noise. Real conversations have all of that, and live comprehension depends on factors this analysis doesn’t capture: speech rate, turn overlap, cultural references, irony, situational context.
The reasonable takeaway: the structures generalize well to written conversational text. Validation with real spoken conversation (with accents, noise, and interruptions) is pending.
Why the hell doesn’t it reach 100%?
Good question. With this specific method, coverage maxes out at ~74%. It’s not a lack of data — it’s three reasons:
A caveat first: this ceiling is not a fundamental property of English. It depends on methodological decisions: n-grams of length 2–5, exclusion of unigrams, lexical and slotted chunks, TV corpus, CELF algorithm. If we changed those variables — allowing longer structures, syntactic dependencies, or semantic models — the percentage would likely change. That said, the concrete reasons for this ceiling are:
1. The lonely unigram problem. The most frequent uncovered tokens are…
| Token | Times appearing uncovered |
|---|---|
| and | 4,297 |
| ‘s (contraction) | 3,797 |
| ‘t (contraction) | 3,674 |
| i | 2,822 |
| yes | 2,386 |
| please | 2,121 |
…ultra-frequent words that appear alone («Yes.», «OK.», «Please.»). My system only selects chunks of 2+ tokens, so these slip through. I could add unigrams, but then the deck would include cards for «the». No thanks.
2. Hellish phraseological combinatorics. Conversational English has almost infinite combinatorics. The same words combine in slightly different ways in every conversation. No finite set of 2–5 length n-grams can capture them all.
3. Long-tail vocabulary. The remaining 25% are technical terms, proper names, neologisms — things that appear once every thousand conversations. They’re not in the top-20K of a TV corpus, nor should they be.
Conclusion: 74% isn’t a failure of the method. It’s a ceiling of this specific method, not a fundamental property of English itself.
The design decision: two decks, not one
The efficiency curve has a clear break at 5,000 chunks. That’s why I split the result into two decks:
| Core (1–5K) | Expansion (5K–10K) | |
|---|---|---|
| DailyDialog coverage | 60.9% | +12.7 pp → 73.6% |
| Effort/impact ratio | Very high | Moderate |
| Learner profile | Beginner–intermediate | Intermediate–advanced |
| Recommendation | Mandatory | Optional (B2+) |
Core: 5,000 structures, 60.9% token coverage. This covers more than half the words in any conversational corpus. This is the deck everyone should study.
Expansion: another 5,000, 73.6% cumulative. The percentage goes up, but the effort per card is much higher. Recommended if you already have a B2 and want to polish.
Deck composition

| Core (1–5K) | Expansion (5K–10K) | |
|---|---|---|
| Bigrams (n=2) | 84.9% | 84.0% |
| Trigrams (n=3) | 11.9% | 11.4% |
| 4-grams (n=4) | 3.2% | 4.5% |
| 5-grams (n=5) | < 0.1% | < 0.1% |
| Lexical | 85.6% | 84.6% |
| Slotted | 14.4% | 15.4% |
Mostly lexical bigrams. The slotted ones (with wildcards) increase slightly in expansion — they’re more specific structures worth learning only once you have the basics.
The 10 most valuable chunks
| # | Pattern | Type | Freq. | Shows | New tokens | Cum. coverage |
|---|---|---|---|---|---|---|
| 1 | in the | lexical | 9,587 | 7 | 19,174 | 0.5% |
| 2 | i don’t | lexical | 9,133 | 7 | 18,266 | 0.9% |
| 3 | you know | lexical | 8,783 | 7 | 17,566 | 1.4% |
| 4 | of the | lexical | 8,749 | 7 | 17,498 | 1.8% |
| 5 | do you | lexical | 8,216 | 7 | 15,543 | 2.6% |
| 6 | are you | lexical | 8,163 | 7 | 16,323 | 2.2% |
| 7 | this is | lexical | 7,033 | 7 | 14,066 | 2.9% |
| 8 | to the | lexical | 6,767 | 7 | 13,534 | 3.3% |
| 9 | going to | lexical | 6,397 | 7 | 12,647 | 3.6% |
| 10 | to {verb} the | slotted | 3,897 | 7 | 11,444 | 3.9% |
Notice: all of them appear in all 7 shows. No show-specific jargon. These are universally conversational structures. And the first slotted one (#10, «to {verb} the») proves that abstract patterns matter too — but far less than pure lexical chunks.
How the cards are designed
I hate cards that show you the abstract pattern («I don’t ___») and expect you to guess. That’s not learning a language — it’s doing a crossword puzzle.
My cards are sentence-first (cloze):
Front:
_____ make of it, but she looked really happy.Back:
I don’t know what to make of it, but she looked really happy.
No sé qué pensar, pero ella parecía muy feliz.
— FRIENDS · #847
The design forces retrieval in context — exactly the skill you need when someone drops a structure in the middle of a conversation and you have to process it in real time.
Each card includes up to 3 example sentences from different shows, with a maximum of 8 examples per show to avoid Doctor Who bias. Spanish translation and TTS audio included.
Who this is for
If you’re learning English and want to optimize your study time (assuming you don’t have time to spare — no one does), these decks are for you.
Instead of memorizing vocabulary lists that never appear together in real life, you’ll learn the structures that appear most in conversational corpora, ranked by their actual impact on token coverage. The first card in the deck («in the») gives you more coverage than the last 5,000 combined.
That’s not marketing. That’s a statistical fact.
Analysis limitations (so you don’t get the wrong idea)
This study has several limitations worth stating clearly:
- TV shows aren’t real conversation. The main corpus is dialogue written by screenwriters. Although the DailyDialog validation shows consistent results, both corpora are clean text without the problems of real speech (accents, noise, stutters, interruptions).
- Token coverage ≠ comprehension. The 74% measures what proportion of words appear in the selected chunks, not how much of a conversation you understand. Real comprehension requires syntax, semantics, pragmatics, and world knowledge that this method doesn’t capture.
- Methodological ceiling, not linguistic. The 74% limit depends on our specific decisions (2–5 n-grams, no unigrams, lexical+slotted chunks). It’s not a universal constant of English.
- No confidence intervals. The results are point estimates. An analysis with cross-validation and bootstrapping would give a more robust picture of variability.
- Generalization to other domains. The corpus is TV shows. Optimal structures for medical, legal, or academic English would be different.
That said, the central finding — diminishing returns are brutal and you should prioritize the first few thousand structures — is robust enough to guide study decisions, even if exact numbers change with different methodologies.
The analysis was solid. The cards weren’t.
Up to this point, everything was fine. The data was solid, the charts looked great, the CELF algorithm was elegant. But when I sat down to actually study with the generated cards, the experience was… meh.
The problem wasn’t the numbers. The problem was that statistical coverage ≠ pedagogical usefulness. And I completely missed that detail.
The cards had five major problems:
- Sitcom context. Learning English from FRIENDS quotes is fine if your life goal is understanding Chandler Bing. For reading a paper, writing a formal email, or having a conversation that doesn’t sound like a TV script, you need more diverse sources.
- No difficulty progression. Card #1 was «in the». Card #847 was «I don’t know what to make of it». There’s no A1→C1, no grammar. It’s like learning to swim by starting from the 10-meter diving board. Raw frequency is not a curriculum.
- No translations or explanations. Knowing that «going to» appears 6,397 times doesn’t tell you what it means or when to use it. The cards were sentence-first, but without a Spanish translation or grammar note. If you already knew the structure, great. If not, you were playing hangman.
- No audio. Learning chunks without hearing them is like learning to sing by reading sheet music. The phonological loop is essential for retention, and I olympically ignored it.
- Too many cards for too little gain. The last 5,000 structures in Expansion contributed less than 1% coverage each. Studying 5,000 cards to gain 6 percentage points is a questionable time investment, to say the least.
The system was an interesting academic exercise — in fact, I think the coverage analysis and the CELF algorithm are the best parts of the project — but as a study tool it was a failure. So I did what any reasonable person would do: threw it in the trash and started over.
FluentForge: what I built instead
The right question wasn’t «what structures appear most in TV shows?» but «what does a Spanish speaker need to understand real English?».
And for that, you don’t need 10,000 chunks from FRIENDS. You need:
- Real frequency vocabulary — not from TV shows, but from linguistic corpora actually designed for this: NGSL (New General Service List), NAWL (New Academic Word List), and NGSL-S (spoken).
- Progressive grammar — from A1 to C1, covering typical Spanish-speaker errors (which aren’t the same as a German or Japanese speaker’s).
- Native audio — every word and every sentence, generated via TTS with Edge-TTS (British Sonia Neural voice).
- Spanish translation and grammar notes — because studying without your L1 is absurd.
FluentForge is an automated pipeline that generates complete Anki decks from real academic sources. No TV shows. No CELF. Pure corpus linguistics applied to teaching.
What’s inside
| # | Deck | Cards | Audio | Type |
|---|---|---|---|---|
| 1 | Core Vocabulary | 5,666 | 5,666 | Vocabulary EN→ES + ES→EN (NGSL) |
| 2 | Grammar & Usage | 1,410 | 1,068 | Cloze Grammar + Phrasal Verbs + Collocations |
| 3 | Real English | 530 | 298 | Lexical Bundles + Idioms + False Friends |
| 4 | Academic Edge | 958 | 1,916 | Academic Vocabulary (NAWL) |
| TOTAL | 8,564 | 8,948 | ||
Each card includes: Spanish translation, phonetic transcription (IPA), POS and CEFR level badges, contextualized example sentence, gender note for cognates, and native audio on both sides. The templates have custom CSS with dark mode — because sometimes you study at 2 AM and your eyes suffer.
Preview
This is what the cards look like in Anki (light mode; they also have dark mode):
Deck index — the 4 decks organized as subdecks:
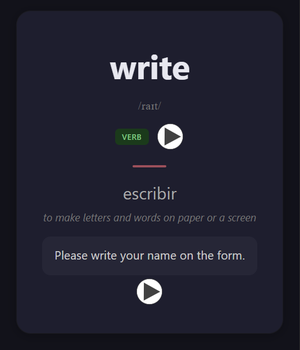
Core Vocabulary — front (EN→ES) and back with translation, IPA, example, and audio:

Grammar & Usage — front (cloze) and back with Spanish grammar explanation:
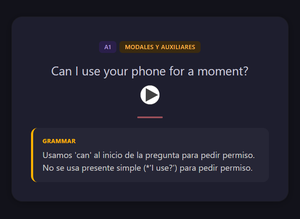
Real English: False Friends — front (Spanish word + incorrect translation) and back with the correction:


How it’s built
The pipeline has 5 phases:
- Phase 0 — Indices: parses two markdown guides (English grammar A1-C1 and lexical bundle taxonomy) and generates JSON indices with 356 atomic grammar points and ~298 multi-word expressions.
- Phase 1 — Normalization: cleans the NGSL, NGSL-S, and NAWL CSVs. This has its quirks: NGSL-S comes in Latin-1 with non-breaking spaces (\xa0), NAWL in UTF-8-BOM with a corrupt entry (DESCENDENT, empty definition), and NGSL has a typo in the header («Definitons» instead of «Definitions»). All of that gets normalized to canonical JSON.
- Phase 2 — LLM Enrichment: uses DeepSeek V4 Flash to generate translations, POS tags, A2-B1 example sentences (for NGSL), and C1 sentences with hint mitigation (for NAWL). For grammar, it generates 3 cloze sentence variants per grammar point using NGSL vocabulary. With automatic retries if the model fails.
- Phase 3 — TTS Audio: Piper TTS generates audio for every word and sentence (~9,000 files). WAV → MP3 192kbps via ffmpeg. Speed adjusted by type: 0.85x for isolated words, 1.0x for sentences, 0.95x for syntax.
- Phase 4 — Build: assembles the .apkg files with genanki, applying category interleaving to avoid semantic interference. Grammar cards are ordered by CEFR (A1 first, C1 last) so your first sessions only see present simple instead of conditional inversions.
Coverage study: how much English does this actually cover?
The question that obsessed LanguageDomain is still valid. But instead of measuring TV chunk coverage over a TV corpus, I measured real vocabulary coverage over a real corpus.
The corpus: 6.3 million tokens from NLTK (Brown, Reuters, Gutenberg, Webtext, inaugural addresses, and State of the Union), divided into 5 registers. Tokenization and lemmatization with NLTK (WordNet + POS tagging).
Results by register
| Register | Size | Total coverage | NGSL alone | NAWL adds |
|---|---|---|---|---|
| Political speeches | 0.5M tokens | 86.27% | 84.56% | +1.35% |
| Academic | 0.5M | 83.66% | 80.98% | +2.27% |
| Fiction (Gutenberg) | 3.0M | 77.24% | 75.93% | +0.82% |
| Conversation (web) | 0.4M | 75.79% | 74.53% | +1.01% |
| News (Reuters) | 1.9M | 74.81% | 72.59% | +1.42% |
| COMBINED | 6.3M | 77.80% | 76.08% | +1.18% |
The stat I love most: NGSL alone (2,809 words) covers 76.08% of tokens. That’s three quarters of English with fewer than 3,000 well-chosen words. NAWL adds another 1.18% — small in percentage, but crucial in academic texts where it reaches 2.27%.
Additionally, 6.89% of sentences contain at least one multi-word expression (bundle, phrasal verb, idiom, or collocation) taught by the decks. The most frequent: according to (1,166 occurrences), as well as (665), kind of (572).
Study limitations
- Aging corpus: Brown is from 1961, Gutenberg from the 19th century. With COCA or BNC, the numbers would likely go up a couple of points.
- NLTK lemmatizer (~93% accuracy): spaCy would be more accurate (~97%) and give slightly higher coverage.
- Conversation = forum text: it’s not real spoken language with accents, noise, and interruptions.
- Token coverage ≠ comprehension: knowing 78% of the words doesn’t mean understanding 78% of what you read. Nation (2006) places the threshold for dictionary-free comprehension at 95-98%.
LanguageDomain vs FluentForge: the comparison
| LanguageDomain | FluentForge | |
|---|---|---|
| Source | 7 TV shows | NGSL, NAWL, grammar guides |
| Items | 10,000 n-gram chunks | 3,790 lemmas + 775 expressions + 356 grammar points |
| Progression | Raw frequency (not pedagogical) | CEFR (A1→C2) + frequency |
| Audio | No | Yes (~9,604 MP3 files) |
| ES translation | No | Yes, on every card |
| Grammar notes | No | Yes, in Spanish, focused on Spanish-speaker errors |
| Phonetic IPA | No | Yes |
| Dark mode | No | Yes |
| Coverage | 74% (20K chunks, TV corpus) | 77.8% (3,790 lemmas, NLTK 6.3M corpus) |
| Efficiency | 0.0037 pp/card | 0.020 pp/card (5.4× better) |
| Verdict | Solid analysis, useless for studying | Studyable, reproducible, data-backed |
The efficiency difference is massive: FluentForge gives you 5.4 times more coverage per card. And these are cards you can actually study without feeling like you’re doing a crossword puzzle.
How to study it (without losing your mind)
The decks are designed to be studied with Anki. Here’s the strategy:
Recommended study order
| Phase | Deck | New cards/day | Approx. duration |
|---|---|---|---|
| 1 | Core Vocabulary | 15–20 | 4–6 months |
| 2 | Grammar & Usage | 10–15 | 2–3 months |
| 3 | Real English | 5–10 | 2–3 months |
| 4 | Academic Edge | 10–15 | 2–3 months |
Start with Core Vocabulary. It covers 76% of English. Without this, the rest is useless. The first 500 words (the most frequent) give you more return than the last 2,000 combined — the same law of diminishing returns we saw in LanguageDomain, but applied to real vocabulary instead of TV chunks.
Grammar & Usage is ordered by CEFR. The first 105 cards are A1 (to be, present simple, there is/are). The last 171 are C1 (inversions, cleft sentences, subjunctive). At 15 new cards a day, the first two weeks you only see basic level. Inversions don’t show up until the seventh week. The progression is natural and doesn’t require any Anki configuration.
Real English and Academic Edge are for later. Lexical bundles make sense once you have context. NAWL academic vocabulary assumes you’ve mastered general vocabulary. Don’t activate them until you’ve spent at least a month with Foundations.
Anki’s SRS does the rest: it shows you each card just before you’re about to forget it. The decks overlap naturally — you don’t need to «finish» one to start the next.
Download
The complete deck in a single .apkg file with all 4 sub-decks and audio — ready to import into Anki 2.1.65+:
Download FluentForge.apkg (140 MB)
Contains: Core Vocabulary (5,666 cards), Grammar & Usage (1,460), Real English (562), Academic Edge (1,916) — 9,604 cards total with 9,604 TTS MP3 audio files.
Instructions: download the file and import it into Anki via File → Import. Audio is embedded in the .apkg itself, no additional installation needed.
Instructions: download the .apkg files and import them into Anki via File → Import. All 4 decks include TTS audio (Sonia Neural voice, Edge-TTS) on every card — ~9,604 MP3 files total. The audio is embedded in the .apkg itself, no additional installation needed.
v2.2 Update (June 2026)
The deck has grown. After using it myself for a few weeks and getting feedback, here’s what changed:
- CEFR sub-decks. Core Vocabulary is no longer a flat 2,833-word deck — it’s now split into A1 (701), A2 (1,373), B1 (438), and B2 (321). Academic Edge is split into B2 and C1. Anki will show you the most frequent words first and level you up naturally, same as the grammar deck.
- Academic Edge production. The academic deck is now bidirectional: you don’t just recognize the word (EN→ES), you produce it (ES→EN). From 958 cards to 1,916. If Foundation has reverse, so does Academic.
- Audio on all decks. Phrasal Verbs, Idioms, Collocations, and False Friends now have TTS audio on every card. All 9,604 audio files cover the entire deck now — no more silent cards.
- +25 C2 grammar points. Literary inversions, lest subjunctive, complex apposition, no sooner… than, double genitives, advanced clefts. From 14 C2 points to 39. For when B2 isn’t enough.
- CEFR labels on all vocabulary. All ~3,800 vocabulary words now show their level (A1 through C1) with a badge. You’ll know whether you’re learning a basic or advanced word.
- More content. +32 idioms (165 total) and +51 collocations (230 total).
- Gender article fix. ~710 verbs had incorrect gender articles in the reverse translation. Fixed.
If you already have v2.1: download the new file and import it. Anki will detect duplicate cards and only add the new ones. Your progress is preserved.
What started as a greedy algorithm over FRIENDS quotes turned into a complete Anki deck generation pipeline. LanguageDomain’s coverage analysis was solid — in fact, it’s the conceptual foundation FluentForge was built on — but the cards weren’t studyable. Sometimes you need to build something, see that it doesn’t work, throw it away, and start over. It’s not cutting-edge science — it’s actually pretty standard: CSVs, LLM calls, TTS, and genanki — but seeing it work is gratifying. If I’ve learned anything, it’s that data without pedagogy is sterile, and that 2,809 well-chosen words take you further than 10,000 TV chunks.