Después de ShadowCoach, me quedé con ganas de más. La herramienta de pronunciación estaba bien, pero cubría solo una parte del aprendizaje: la parte mecánica de repetir sonidos. Lo que realmente quería era practicar conversación de verdad. Tener a alguien —o algo— con quien hablar, que me entendiera, que me respondiera, y que lo hiciera en inglés sin depender de una conexión a internet.
Existían opciones, claro. ChatGPT, Google Assistant, todas las que ya conocemos. Pero para practicar inglés quería algo específico: poder cambiar de modelo según lo que necesitara, elegir la voz que me diera la gana, y sobre todo, que todo pasara en mi máquina sin enviar micrófono a ningún servidor. Y de paso, como soy ingeniero, quería montármelo yo para entender cómo encajan todas las piezas.
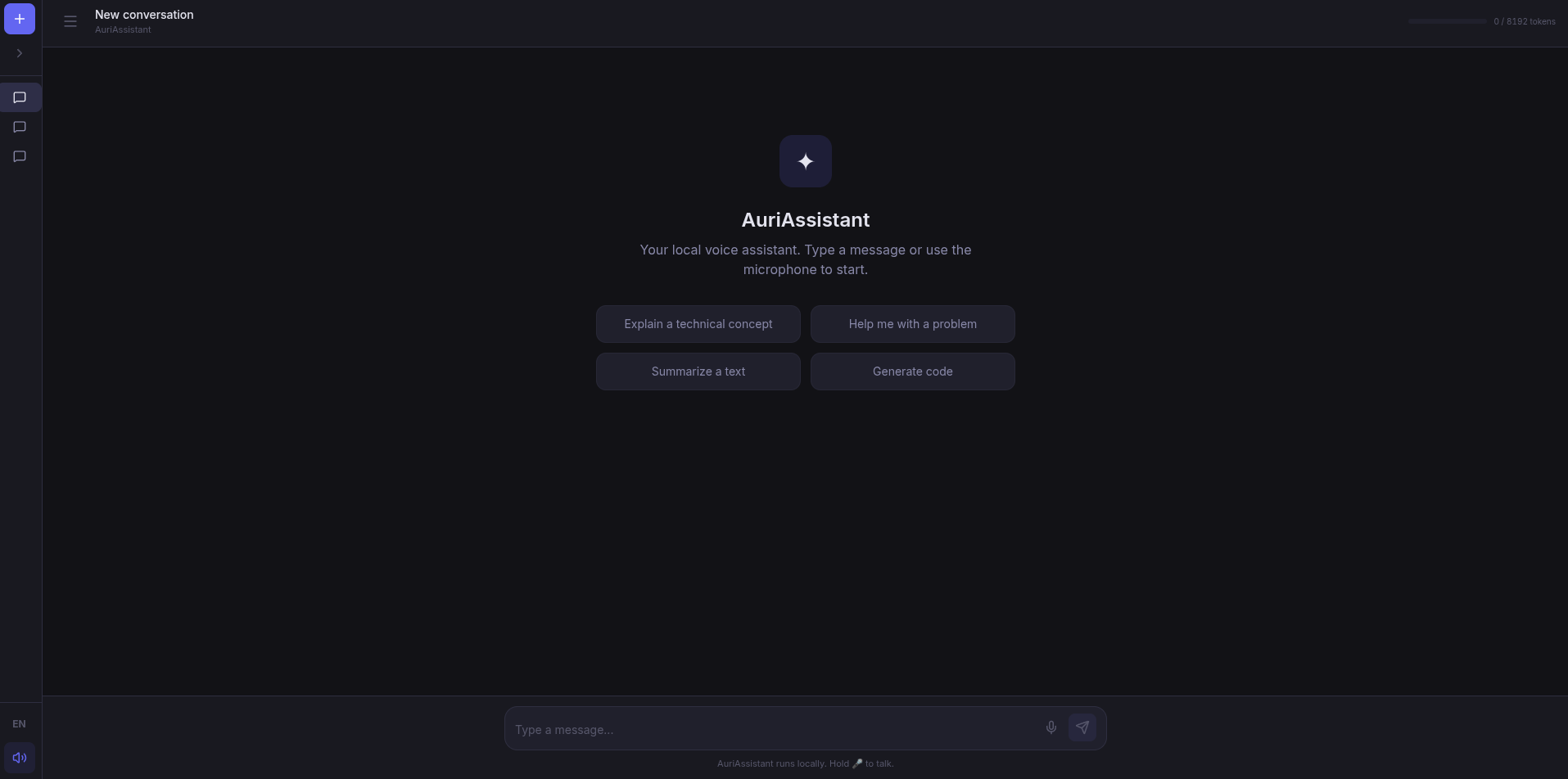
El viaje empieza con un botón de micrófono
La idea original era sencilla: un chat al que pudieras hablarle. Nada más. Aprietas un botón, hablas, la IA te entiende y te responde con voz. Como un walkie-talkie con un cerebro dentro.
El flujo es el que puedes imaginarte:
- Mantienes pulsado un botón y hablas
- El audio se transcribe con Whisper (local, en GPU)
- El texto se manda a un modelo de lenguaje (LLaMA, Qwen, el que tengas cargado)
- La respuesta se convierte a voz con Kokoro y la escuchas
Parece simple, y conceptualmente lo es. El trabajo estaba en hacer que esas cuatro piezas funcionaran juntas sin romper nada, en tiempo real, y todo dentro de Docker.
De práctica de inglés a asistente polivalente
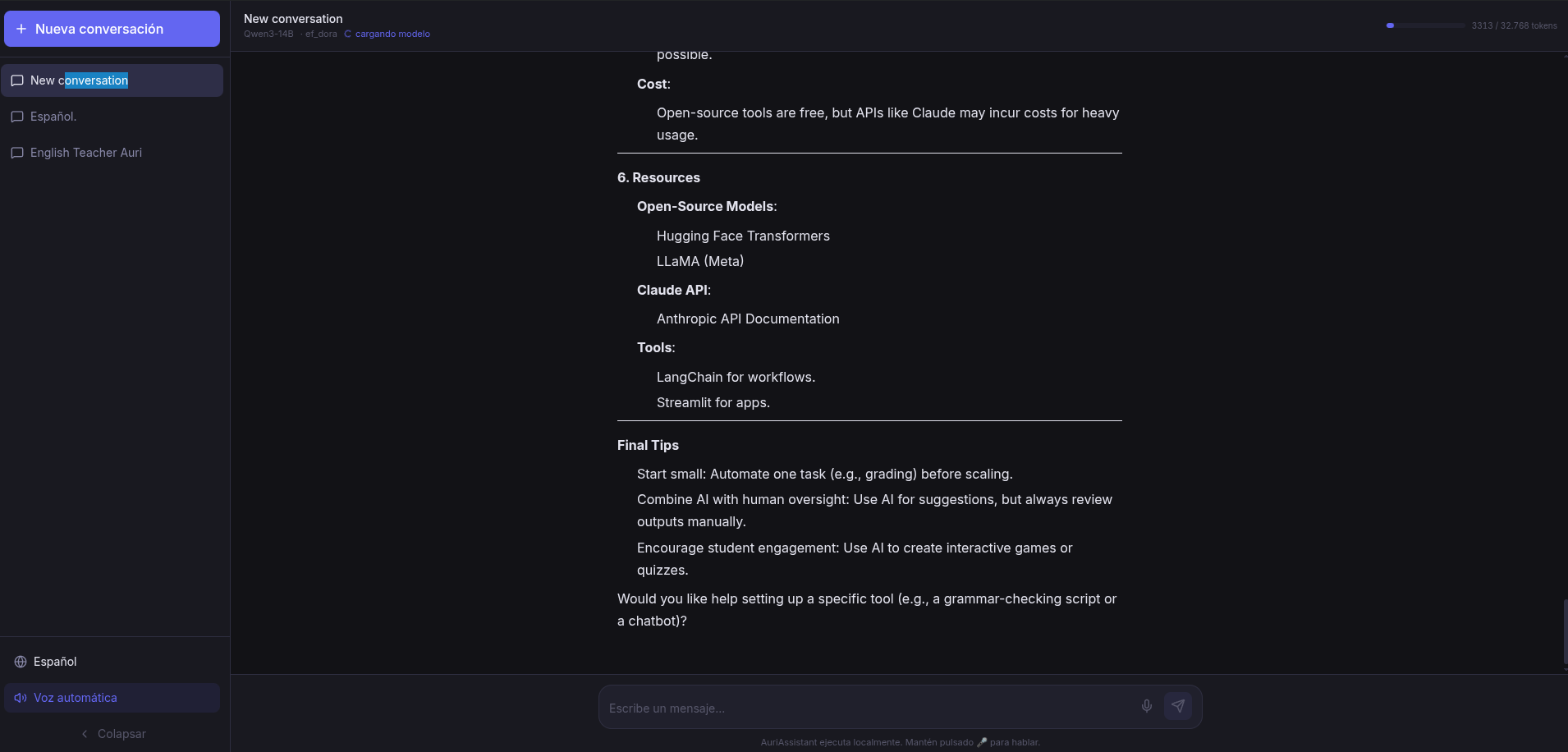
Lo divertido llegó cuando empecé a usarlo. La versión inicial estaba enfocada en inglés: system prompt fijo, voces en inglés americano, todo pensado para practicar. Pero en cuanto lo tuve funcionando, me di cuenta de que había construido algo más grande.
Si cambiaba el system prompt, el asistente se convertía en otra cosa. Un experto en Python. Un corrector de textos. Un compañero de lluvia de ideas. Un profesor de historia. Cualquier rol que se me ocurriera. Y si cambiaba la voz, sonaba diferente. Y si cambiaba el modelo, pensaba diferente.
Lo que empezó como «una app para practicar inglés» se convirtió en «una plataforma de asistentes configurables». Cada conversación tiene su propio prompt, su modelo, su voz, su temperatura. Es como tener un ejército de bots personales, cada uno especializado en algo, y todos funcionando en local.
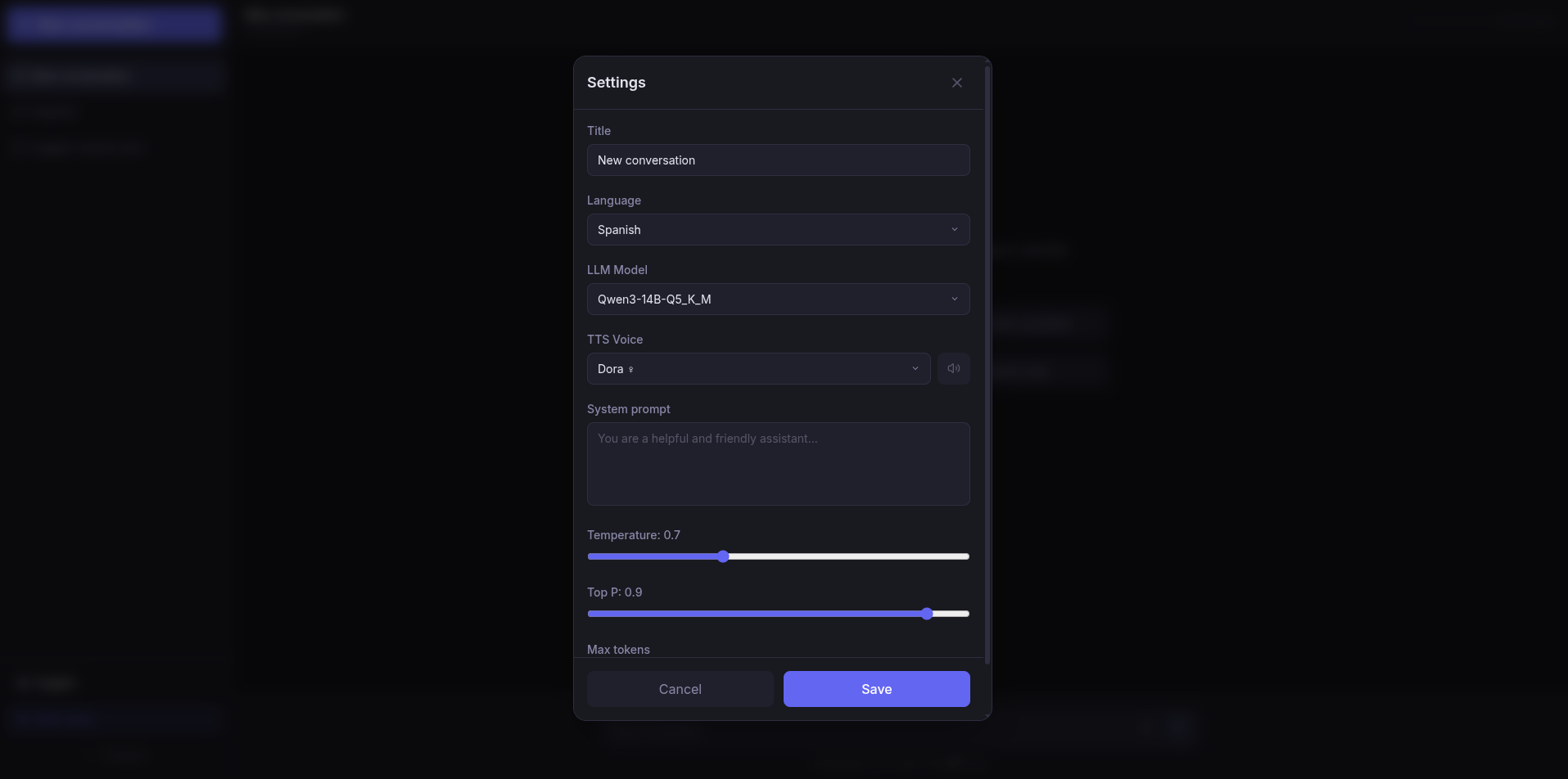
Cómo está montado
La arquitectura es un poco más bestia que la de ShadowCoach. Aquí hay cinco servicios que se orquestan con Docker Compose:
- Frontend: React 19 con Vite y Tailwind. Nada especialmente llamativo visualmente, pero funcional. Mensajes con markdown, indicador de contexto, selector de modelos y voces.
- Backend: FastAPI con SQLAlchemy asíncrono. Orquesta todo: recibe los mensajes, los envía al modelo que toca, gestiona las conversaciones, el historial, la compactación del contexto… Es el cerebro operativo.
- LLM: llama-cpp-python con una sola GPU. Carga un modelo GGUF cada vez y lo sirve con API compatible con OpenAI. Swap de modelos dinámico: cambio el modelo en caliente y en 2-5 segundos está listo.
- STT: whisper.cpp compilado a C++. Ni una línea de Python. Solo un binario que transcribe audios a velocidad endiablada.
- TTS: Kokoro con PyTorch. Voces naturales, 50 voces diferentes, 8 idiomas. De lo mejorcito que he visto en TTS local.
La gracia está en que todo corre sin internet. No hay llamadas a OpenAI, no hay API keys, no hay datos que salgan de casa. Es mío de verdad.
La parte técnica que más me gustó
Lo que más disfruté fue montar el streaming por WebSocket. Cuando envías un mensaje, el backend abre un WebSocket, manda la petición al LLM, y conforme van saliendo tokens los va reenviando al frontend. Ves la respuesta en tiempo real, palabra por palabra, como si estuvieras chateando con alguien al otro lado.
El frontend además parsea los bloques
Otra cosa que mola es la compactación de conversaciones. Cuando el contexto se llena, puedes pedirle al propio LLM que resuma todo lo hablado hasta ahora. Ese resumen se guarda como mensaje de sistema y se borra el historial anterior. Es como limpiar la pizarra sin perder lo importante.
Lo que me llevo
Este proyecto me confirmó algo que ya sospechaba: montar tus propias herramientas es una de las mejores formas de aprender. No solo sobre la tecnología en sí —Docker, FastAPI, WebSockets, modelos de lenguaje— sino sobre cómo diseñar sistemas que realmente funcionen para lo que necesitas.
La app empezó siendo una cosa y terminó siendo otra muy distinta, y eso está bien. A veces el mejor producto es el que evoluciona según lo usas y descubres lo que realmente necesitas.
Y de paso, ahora tengo un asistente que me ayuda con el inglés, con el código, con los textos, y con lo que se me ocurra. Todo local, todo mío.
El código está en GitHub con licencia MIT. Necesitas Docker, una GPU NVIDIA con al menos 8 GB de VRAM y ganas de trastear.